Why is ClickHouse so Fast? The Architecture Behind Lightning-Speed Analytics
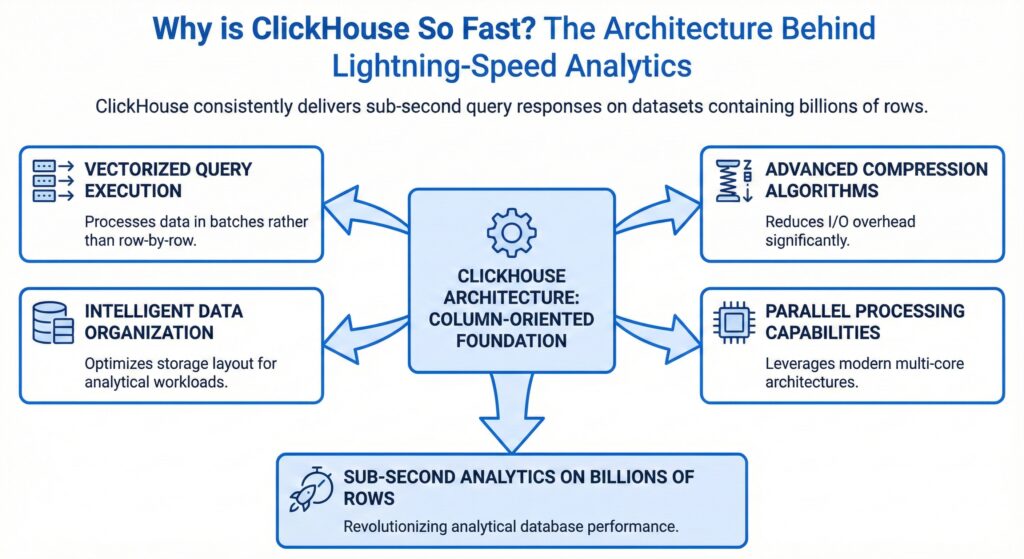
ClickHouse has revolutionized the world of analytical databases with its exceptional performance capabilities. While many databases claim to be fast, ClickHouse consistently delivers sub-second query responses on datasets containing billions of rows. But what makes this column-oriented database so remarkably fast compared to its competitors?
The Foundation: Column-Oriented Architecture
Beyond Basic Column Storage
While ClickHouse’s column-oriented design is fundamental to its speed, it’s far from the only factor. The database implements several architectural innovations that work together to create a performance powerhouse:
- Vectorized query execution – Processes data in batches rather than row-by-row
- Advanced compression algorithms – Reduces I/O overhead significantly
- Intelligent data organization – Optimizes storage layout for analytical workloads
- Parallel processing capabilities – Leverages modern multi-core architectures
Storage Layer Innovations
Optimized Data Structures
Employs sophisticated storage mechanisms that go beyond traditional column stores:
-- Example: MergeTree engine with optimized partitioning
CREATE TABLE analytics_data (
date Date,
user_id UInt64,
event_type String,
value Float64
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(date)
ORDER BY (date, user_id);
Key Storage Features
- MergeTree Engine Family – Provides automatic data merging and optimization
- Sparse Indexing – Reduces memory usage while maintaining query speed
- Data Compression – Achieves compression ratios of 10:1 or higher
- Partition Pruning – Eliminates unnecessary data scanning
Advanced Compression Techniques
ClickHouse implements multiple compression algorithms optimized for different data types:
- LZ4 – Fast compression for general use cases
- ZSTD – Higher compression ratios for storage optimization
- Delta encoding – Efficient for time-series and sequential data
- Dictionary compression – Optimal for categorical data
Query Processing Layer Excellence
Vectorized Execution Engine
Unlike traditional databases that process queries row-by-row, uses vectorized execution:
// Simplified example of vectorized processing
void processColumn(const Column& input, Column& output) {
const auto* data = input.getData();
auto* result = output.getMutableData();
// Process entire blocks at once using SIMD instructions
for (size_t i = 0; i < input.size(); i += VECTOR_SIZE) {
vectorizedOperation(data + i, result + i, VECTOR_SIZE);
}
}
Parallel Query Execution
ClickHouse automatically parallelizes queries across multiple CPU cores:
- Thread-per-core architecture – Maximizes CPU utilization
- Lock-free data structures – Eliminates contention bottlenecks
- NUMA-aware scheduling – Optimizes memory access patterns
- Dynamic work distribution – Balances load across available resources
Memory Management Optimizations
Efficient Memory Allocation
ClickHouse implements custom memory allocators designed for analytical workloads:
- Arena allocators – Reduce memory fragmentation
- Memory pools – Minimize allocation overhead
- Cache-friendly data layouts – Improve CPU cache utilization
- Memory mapping – Leverages OS-level optimizations
Cache Optimization Strategies
The database employs multiple caching layers:
- Mark cache – Stores index information for fast data location
- Uncompressed cache – Keeps frequently accessed data in memory
- Compiled expression cache – Reuses optimized query execution plans
- OS page cache – Leverages system-level caching mechanisms
Network and I/O Optimizations
Minimized Data Transfer
ClickHouse reduces network overhead through several techniques:
-- Example: Projection optimization
SELECT
toYYYYMM(date) as month,
count(*) as events,
avg(value) as avg_value
FROM analytics_data
WHERE date >= '2024-01-01'
GROUP BY month;
-- Only required columns are read and transferred
Asynchronous I/O Operations
- Non-blocking disk operations – Prevents I/O bottlenecks
- Prefetching strategies – Anticipates data access patterns
- Batch I/O operations – Reduces system call overhead
- Direct I/O support – Bypasses OS buffer cache when beneficial
Code Generation and Compilation
Runtime Code Optimization
ClickHouse generates optimized machine code for frequently executed queries:
- LLVM-based compilation – Creates highly optimized execution paths
- Expression compilation – Eliminates interpretation overhead
- Specialized functions – Generates code tailored to specific data types
- Inlining optimizations – Reduces function call overhead
Distributed Architecture Benefits
Horizontal Scaling Capabilities
ClickHouse’s distributed architecture contributes significantly to its performance:
- Shared-nothing architecture – Eliminates coordination overhead
- Local data processing – Minimizes network communication
- Automatic load balancing – Distributes queries efficiently
- Fault tolerance – Maintains performance during node failures
Real-World Performance Comparisons
Benchmark Results
ClickHouse consistently outperforms competitors in analytical workloads:
- Query latency – Often 10-100x faster than traditional databases
- Throughput – Handles millions of inserts per second
- Compression – Achieves better storage efficiency
- Concurrent users – Supports thousands of simultaneous queries
Best Practices for Maximum Performance
Optimization Strategies
To leverage ClickHouse’s speed advantages:
- Choose appropriate table engines – MergeTree family for most use cases
- Design effective partition keys – Enable partition pruning
- Optimize column order – Place frequently queried columns first
- Use appropriate data types – Minimize storage overhead
- Implement proper indexing – Leverage sparse indexes effectively
Conclusion
ClickHouse’s exceptional speed results from a combination of architectural innovations spanning both storage and query processing layers. Its column-oriented foundation, vectorized execution engine, advanced compression techniques, and intelligent memory management work together to deliver unparalleled analytical performance.
The database’s success lies not in any single optimization, but in the careful integration of multiple performance-enhancing technologies. From custom memory allocators to runtime code generation, every component is designed with speed as the primary objective.
For organizations dealing with large-scale analytical workloads, ClickHouse represents a paradigm shift in what’s possible with modern database technology. Its ability to process billions of rows in milliseconds makes it an invaluable tool for real-time analytics, business intelligence, and data-driven decision making.
Whether you’re building a real-time dashboard, conducting complex analytical queries, or processing massive data streams, ClickHouse’s architectural advantages provide the performance foundation needed for modern data applications.
Further Reading:
- An Introduction to Time-Series Databases: Powering Modern Data-Driven Applications
- ClickHouse® ReplacingMergeTree Explained: The Good, The Bad, and The Ugly
- Pro Tricks to Build Cost-Efficient Analytics: Snowflake vs BigQuery vs ClickHouse® for Any Business
- Using ClickHouse-Backup for Comprehensive ClickHouse® Backup and Restore Operations
- Avoiding ClickHouse Fan Traps : A Technical Guide for High-Performance Analytics
- ClickHouse official Documentation