Comparing Columnar Databases vs Row-based Databases
In the dynamic landscape of data management, the choice between columnar stores and ROW-based databases has a profound impact on performance, especially in scenarios requiring rapid data retrieval and analytical prowess. These two approaches, though fundamentally different, offer unique strengths that cater to specific use cases. By delving into a real-life example of a sales database, we can unravel the intricate differences between these methodologies and understand why columnar stores often outpace traditional ROW-based relational database management systems.
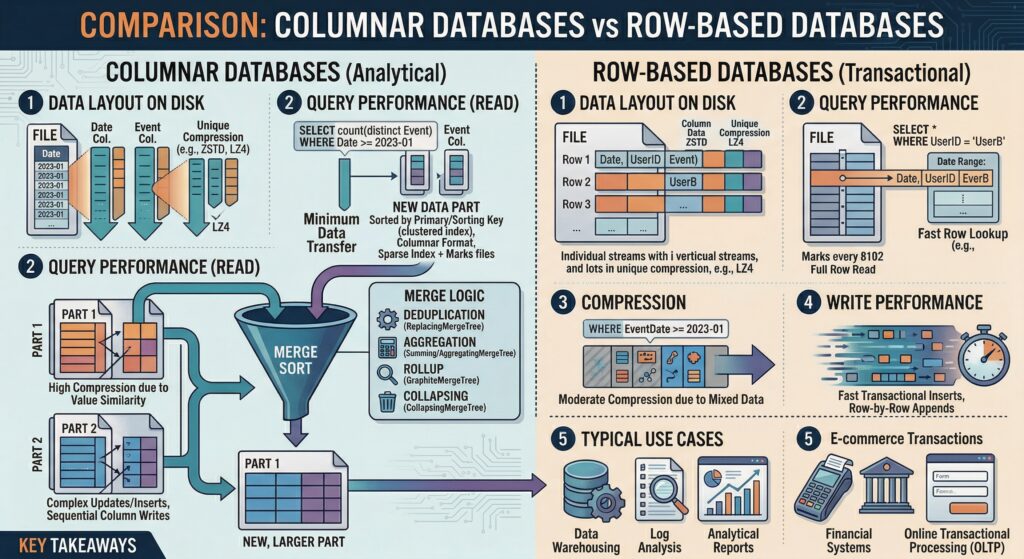
ROW-based database systems and columnar stores are two distinct approaches to storing and retrieving data in a relational database management system (RDBMS). Let’s compare these approaches using a real-life example and understand why columnar stores often offer superior performance.
Performance Comparison
-
Compression Efficiency:
- In columnar stores, data within each column is homogeneous (same data type), enabling highly efficient compression techniques.
- Common methods include:
- Run-length encoding (RLE): Effective for columns with repeated values (e.g., status flags, categorical data), storing a value once with a count of consecutive occurrences.
- Dictionary encoding: Replaces repetitive string values (e.g., product names, country codes) with compact integer indices, reducing storage and improving comparison speed.
- Delta encoding: Stores the difference between consecutive values in sorted numeric or timestamp columns, which often results in small, easily compressible integers.
- Bit-packing: Efficiently stores fixed-width integers or booleans by using only the necessary number of bits.
- Homogeneous data types allow statistical compression algorithms to model value distributions more accurately, increasing compression ratios.
- Reduced data size translates directly to lower I/O bandwidth requirements during queries, faster disk reads, and improved cache utilization.
- In contrast, row-based stores interleave multiple data types within the same block, limiting compression efficiency due to data heterogeneity.
-
Query Performance (Selective Column I/O):
- Columnar databases read only the columns explicitly referenced in a query, minimizing physical I/O.
- For example, a query aggregating SUM(Quantity) for a specific product accesses only the Quantity and ProductID columns, skipping irrelevant fields like CustomerName, Address, or OrderTimestamp.
- This selective access drastically reduces the volume of data transferred from storage to memory, especially beneficial in wide tables with dozens or hundreds of columns.
- Row-based systems retrieve entire rows regardless of how many columns are needed, leading to unnecessary disk I/O and increased memory pressure.
- The performance gap widens as table width increases, making columnar storage significantly more efficient for sparse queries.
-
Aggregation and Analytics Workloads:
- Columnar formats are optimized for analytical operations such as SUM, COUNT, AVG, MIN, MAX, and GROUP BY.
- Aggregation functions operate directly on contiguous blocks of column data, allowing for sequential memory access patterns that align well with CPU cache lines.
- Since columnar data is stored in compressed format, modern engines can perform computations on compressed data (e.g., summing run-length encoded sequences without full decompression), further accelerating processing.
- Memory locality is enhanced because all values for a given metric are stored adjacently, reducing cache misses and improving throughput.
- Row-based systems require deserializing entire records, extracting relevant fields, and then performing calculations—introducing significant overhead in both CPU and memory usage.
-
Predicate Pushdown:
- Columnar storage formats (e.g., Apache Parquet, ORC) include per-column and per-data-block metadata such as minimum and maximum values, null counts, and bloom filters.
- Predicate pushdown allows the query engine to evaluate WHERE clause conditions at the storage level, skipping entire data blocks that cannot contain matching rows.
- For instance, a query filtering WHERE SaleDate BETWEEN ‘2023-01-01’ AND ‘2023-12-31’ can skip reading blocks where the
SaleDatecolumn’s max value is before 2023 or min value is after 2023. - This pruning reduces I/O and speeds up query execution by avoiding unnecessary data loading.
- While some row-based systems support predicate pushdown, the lack of column-level metadata and storage segregation limits its effectiveness.
-
Vectorized Processing:
- Columnar databases naturally support vectorized query execution, where operations are performed on batches of values (vectors) instead of one row at a time.
- Data is processed in columnar arrays, enabling the use of SIMD (Single Instruction, Multiple Data) CPU instructions to perform arithmetic or logical operations on multiple values simultaneously.
- For example, adding two 1024-element numeric columns can be done in parallel using vector addition instructions, achieving significant speedups over scalar processing.
- Vectorized engines reduce instruction overhead and improve CPU utilization by minimizing branch mispredictions and loop control costs.
- The contiguous layout of columnar data ensures predictable memory access patterns, further enhancing vectorization efficiency.
- Row-based systems face challenges in vectorization due to data layout fragmentation and the need for complex data extraction before batch processing.
Conclusion
In the realm of data management, where speed, efficiency, and analytical capabilities reign supreme, the contrast between columnar stores and ROW-based databases becomes increasingly pronounced.
The real-life example of a sales database unveils how columnar stores, through their innovative storage architecture and query optimizations, consistently outperform traditional ROW-based systems in scenarios demanding rapid data retrieval and analytical processing.
This exploration underscores the significance of aligning database design with specific use cases. In the realm of performance-driven data management, columnar stores emerge as an enticing solution for those seeking unparalleled speed and analytical prowess.
Further Reading
- ChistaDATA University
- ClickHouse Consulting
- ClickHouse Support
- ClickHouse Managed Services
- ClickHouse Break Fix Engineering Services