In the world of data analytics, speed is of the essence. ClickHouse, an innovative columnar database management system, has gained prominence for its exceptional query performance. At the heart of this prowess lies ClickHouse’s vectorized query processing approach, a sophisticated technique that allows it to perform operations on data columns in a lightning-fast manner. This article delves into the mechanics of ClickHouse’s vectorized processing, unraveling its inner workings and elucidating the advantages it brings to the realm of data analytics.
ClickHouse is renowned for its exceptional query performance, owed in large part to its vectorized query processing approach. Unlike traditional row-based systems, ClickHouse leverages the power of columnar data storage combined with vectorized processing techniques to achieve unparalleled query execution speeds. In this article, we will delve into ClickHouse’s vectorized query processing, exploring its mechanisms, benefits, and real-world implications.
Understanding Vectorized Processing
Vectorized processing involves performing operations on entire vectors (columns) of data in a single instruction, rather than processing one element (row) at a time. This approach is particularly suited for analytical workloads that involve aggregations, filtering, and transformations, as seen in data warehouses and analytical databases.
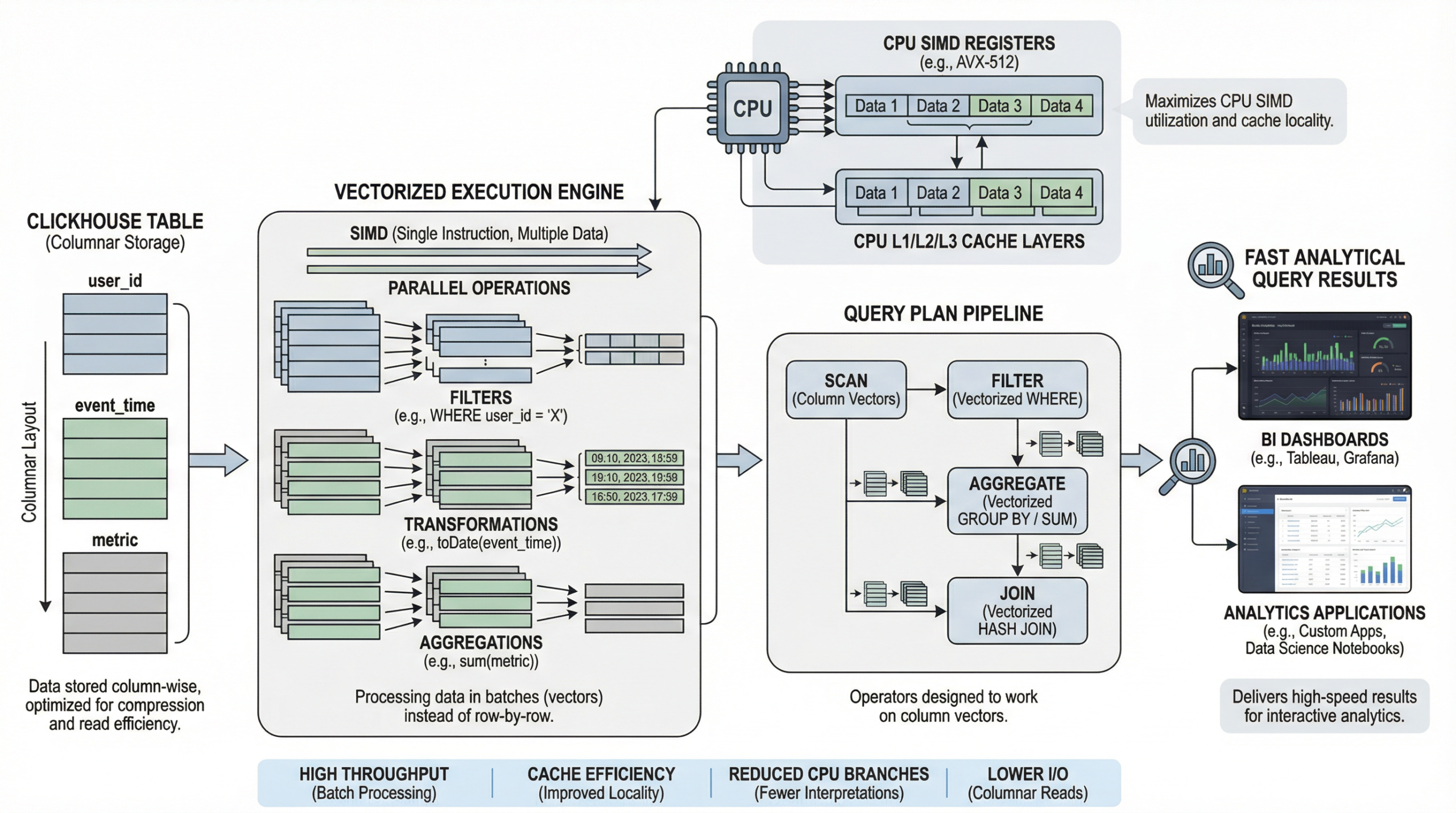
ClickHouse’s Vectorized Execution
ClickHouse’s vectorized processing operates as follows:
- Data Loading and Storage: ClickHouse stores data in columns, allowing it to read only the required columns during query execution. This minimizes I/O operations and improves data locality.
- Batch Processing: Queries are divided into batches, with each batch containing a fixed number of rows. Instead of executing operations row by row, ClickHouse processes entire batches in one go.
- SIMD Instructions: ClickHouse exploits Single Instruction, Multiple Data (SIMD) instructions supported by modern CPUs. SIMD allows executing a single operation on multiple data elements simultaneously, significantly accelerating calculations.
- Columnar Operations: ClickHouse’s algorithms are designed to perform operations on entire columns, making use of SIMD instructions. For example, aggregations like SUM, COUNT, and AVG are applied to entire vectors.
- Memory Efficiency: Vectorized processing improves cache efficiency. Since data in a column is stored together, fetching a column into memory brings in a contiguous block of data, reducing cache misses.
- Expression Trees: ClickHouse compiles queries into expression trees, optimizing them for vectorized execution. The query planner generates plans that facilitate efficient columnar operations.
Benefits of Vectorized Processing
- Increased Throughput: Vectorized processing drastically reduces the overhead of looping through individual rows. This leads to higher query throughput and better response times.
- Optimized for Analytics: Analytical queries often involve aggregations and transformations on large datasets. Vectorized processing is tailored for these operations, resulting in faster execution.
- Efficient Use of Hardware: By harnessing SIMD instructions and maximizing memory locality, ClickHouse makes the most of modern hardware capabilities.
- Reduced Latency: Vectorized processing minimizes context switches between CPU operations, further reducing query execution time.
Real-World Implications
Let’s consider a scenario where you need to calculate the total sales of a specific product across millions of transactions. ClickHouse’s vectorized processing allows it to fetch the “Quantity” column and perform aggregation operations on it, resulting in significantly faster calculations compared to row-based systems.
Conclusion
In the ever-evolving landscape of data management, ClickHouse’s vectorized query processing stands as a testament to the relentless pursuit of performance optimization. By capitalizing on columnar data storage, batch processing, SIMD instructions, and optimized expression trees, ClickHouse achieves what was once deemed unattainable: the ability to process vast datasets with unprecedented efficiency. As organizations increasingly rely on data-driven insights for critical decisions, ClickHouse’s vectorized processing emerges as a foundational pillar in the architecture of high-speed analytical engines, empowering users to extract meaningful insights from their data at unprecedented speeds.
To know more about Vectorized Query Processing in ClickHouse, do read the following articles:
- ClickHouse Performance: Overview of Vectorized Query Processing in ClickHouse
- ClickHouse Performance: Advanced Optimizations for Ultra-low Latency
- Avoiding Costly Mistakes: Profile Events and Query Traces in a Single ClickHouse Query
- SQL Antipatterns in ClickHouse
- Monitoring Merge Queues in ClickHouse