Introduction
Columnar databases, also known as ColumnStores, are a type of database that stores and organizes data by columns rather than by rows. These types of databases are optimized for analytics and reporting workloads, as they allow for faster data retrieval and aggregation.
Row-based databases, on the other hand, store and organize data by rows. These types of databases are optimized for transactional workloads, as they allow for fast data insertion and update operations.
ColumnStores are more suitable for analytics workloads because they allow for faster data retrieval and aggregation. This is because columnar databases store data in a column-wise format, allowing for more efficient compression and encoding. This means that only the columns that are needed for a particular query need to be read from the disk, reducing the I/O required for the query.
Additionally, ColumnStores are optimized for reading large amounts of data, whereas row-based databases are optimized for inserting and updating small amounts of data. ColumnStores can read large amounts of data much faster than row-based databases, making them more suitable for analytics workloads.
However, ColumnStores are not suitable for transactional workloads. In transactional workloads, row-based databases are more efficient because they allow for fast data insertion and update operations. Also, ColumnStores may have a harder time dealing with updates and deletions, which need to be handled differently compared to reading operations.
How is data stored in a ColumnStore?
In a ColumnStore, data is stored and organized by column rather than by row, as in traditional row-based database systems. This means that all the values for a particular column are stored together rather than being spread out across multiple rows.
Here’s an example of how data would be stored in an RDBMS (row-based) for a simple table with three columns (A, B, C):
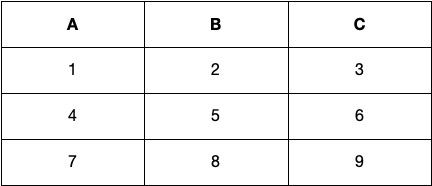
In a columnstore, the data would be stored as follows:
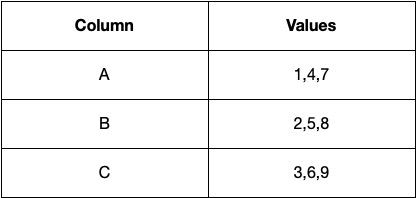
This way of organizing data allows for more efficient data retrieval and aggregation, as the values for a particular column are stored together. This allows for more efficient compression and encoding, resulting in faster query execution times and less I/O required.
A columnstore database can also have different types of indexes that can be used depending on the type of queries that needs to be performed. For example, a bitmap index is an index used to quickly find all the rows that match a particular value in a column, while a dictionary index is an index used to quickly find a particular value in a column. This allows the columnstore to be highly efficient in query execution.
In summary, data in a columnstore is stored and organized by column, allowing for more efficient data retrieval and aggregation, better compression, and encoding and support for different types of indexes. This allows for faster query execution times and less I/O required.
Why are ColumnStores faster for Data Analytics than Row-based DBs?
ColumnStores are faster for data analytics than row-based database systems for several reasons:
- Column pruning: ColumnStores only retrieve and process the required columns for a particular query, which reduces the amount of data that needs to be read and processed. This results in faster query execution times and less I/O required.
- Vectorized Processing: ColumnStores process data in large chunks or “vectors” at a time, which allows for more efficient processing. This is because the CPU can execute multiple operations in parallel on the same data, resulting in faster query execution times.
- Compression: ColumnStores use efficient compression techniques that reduce the amount of data that needs to be read and processed. This results in faster query execution times and less I/O required.
- Data organization: ColumnStores organize data in a column-wise format, which allows for more efficient data retrieval and aggregation. This is because data is stored and organized by column, which allows for more efficient compression and encoding, resulting in faster query execution times and less I/O required.
- Filter pushdown: ColumnStores can push filtering conditions down to the storage layer, which allows for filtering out unnecessary data before it’s read into memory. This results in faster query execution times and less I/O required.
- Time-series specific features: Some ColumnStore databases like TimescaleDB, InfluxDB and ClickHouse have built-in time-series specific features like Retention policies, downsampling, and time-based queries that make it more efficient for time-series data analytics.
In contrast, row-based databases are optimized for transactional workloads, where data is inserted and updated frequently. Row-based databases store data in a row-wise format, which makes it harder to compress and encode efficiently, and it’s not optimized for data retrieval and aggregation.
How Vectorized Query Processing benefits Columnar Databases?
Vectorized query processing is a technique that can greatly benefit Columnar databases by allowing the CPU to execute multiple operations in parallel on the same data, reducing the amount of memory required, allowing for predicate pushdown, better compression, and better handling of null values, resulting in faster query execution times and less I/O required:
- CPU Optimization: Vectorized processing allows the CPU to execute multiple operations in parallel on the same data, which can greatly improve query execution times. By processing data in large chunks, the CPU can work on multiple data elements simultaneously, reducing the number of instructions required to process the data.
- Memory Optimization: Vectorized processing allows Columnar databases to read and process data in large chunks, which can greatly reduce the amount of memory required to process a query. By reading and processing data in large chunks, the database can reduce the number of memory accesses required, which can improve query execution times and reduce memory usage.
- Predicate pushdown: Vectorized processing allows for predicate pushdown, which allows for filtering out unnecessary data before it’s read into memory. This can greatly improve query execution times by reducing the amount of data that needs to be read and processed.
- Better compression: Vectorized processing allows Columnar databases to use more efficient compression techniques, like Run Length Encoding, that can greatly improve compression ratios, resulting in faster query execution times and less I/O required.
- Better handling of NULL values: Vectorized processing allows Columnar databases to handle null values in a more efficient way, by using a bitmap to indicate which values are null, instead of storing null values for each column.
C++ algorithm to implement vectorized query computing
Vectorized query computing can be implemented in C++ using SIMD (Single Instruction, Multiple Data) instructions. SIMD instructions allow the CPU to perform the same operation on multiple data elements simultaneously. Here is an example C++ algorithm for vectorized query computing using SIMD instructions:
#include <immintrin.h> // Include SIMD header
const int VECTOR_SIZE = 8; // Number of elements in the vector
void vectorized_query_computing(float* data, int size) {
for (int i = 0; i < size; i += VECTOR_SIZE) {
__m256 vector = _mm256_load_ps(&data[i]); // Load data into vector
vector = _mm256_sqrt_ps(vector); // Perform square root operation on vector
_mm256_store_ps(&data[i], vector); // Store result back to memory
}
}
In this example, the algorithm loads 8 data elements into a vector using the _mm256_load_ps() function, then performs the square root operation on the entire vector using the _mm256_sqrt_ps() function. Finally, the result is stored back to memory using the _mm256_store_ps() function. The algorithm iterates through the data array in chunks of 8 elements at a time, thus taking advantage of SIMD instructions to process multiple elements simultaneously.
How ColumnStores compress data more efficiently than row-based database systems?
ColumnStores compress data more efficiently than row-based databases because they store data in a column-wise format, which allows for better compression and encoding techniques.
- Dictionary Encoding: ColumnStores use dictionary encoding to compress data. This technique replaces repetitive values with a smaller integer. This means that only unique values are stored, reducing the amount of storage space required.
- Run Length Encoding: ColumnStores also use run-length encoding to compress data. This technique replaces consecutive repeated values with a single value and a count. This can result in significant compression for columns with many repeated values.
- Bit-packing: ColumnStores use bit-packing to compress data. This technique stores multiple values in a single byte, reducing the storage space required.
- Compression of null values: ColumnStores are also able to compress null values by using a bitmap to indicate which values are null, instead of storing null values for each column.
- Column pruning: ColumnStores can only retrieve and process the required columns for a particular query, resulting in less data to read and less data to compress, reducing the I/O required for the query.
These techniques are not feasible or efficient in row-based databases because they store data in a row-wise format. In row-based databases, the data is stored in a fixed-size format, which makes it harder to compress and encode efficiently. Also, in row-based databases, all the columns need to be read and processed for a query, which increases the I/O required for the query and reduces the performance.
Why are B-Tree indexes not recommended for Analytical Query Processing (OLAP) Platforms?
B-Tree index is a popular index structure that is widely used in relational databases for transactional workloads. However, B-Tree index may not be the best option for analytical queries for several reasons:
- Large number of seeks: B-Tree index is optimized for point lookups, which means that it needs to perform multiple seeks to retrieve data for a single query. This can greatly increase the I/O cost of the query, and slow down query execution times.
- Limited parallelism: B-Tree index is designed to be used by a single thread, which means that it is not well-suited for parallel query execution. This can greatly limit the scalability of the database, and slow down query execution times.
- Lack of compression: B-Tree index stores data in a row-wise format, which makes it harder to compress and encode efficiently. This can greatly increase the amount of I/O required to process a query, and slow down query execution times.
- High memory usage: B-Tree index requires a large amount of memory to store the index, which can greatly increase the memory usage of the database. This can limit the scalability of the database, and slow down query execution times.
- Not well-suited for aggregation: B-Tree index is not well-suited for aggregation operations, which are common in analytical queries. This can greatly increase the complexity of the query, and slow down query execution times.
Why use ClickHouse for real-time Data Analytics?
ClickHouse is a column-store, open-source, analytics database that is optimized for real-time data analytics. There are several reasons why ClickHouse is a great choice for real-time data analytics:
- High Performance: ClickHouse is designed to handle large amounts of data, and can process billions of rows per second on a single server, making it a great choice for real-time data analytics.
- Scalability: ClickHouse is a distributed database that can scale horizontally, allowing you to add more servers as your data grows, which makes it easy to scale up to handle large amounts of data.
- Column-store: ClickHouse stores data in a column-wise format, which allows for efficient compression and encoding of data, resulting in faster query execution times and less I/O required.
- SQL support: ClickHouse supports ANSI SQL, making it easy to use for developers and data analysts who are familiar with SQL.
- Low Latency: ClickHouse is designed to have low latency, which means that queries are executed quickly, making it a great choice for real-time data analytics.
- Asynchronous inserts: ClickHouse allows for Asynchronous inserts which allows for inserting data into the table without waiting for the data to be written to disk, which results in faster insert performance.
- Flexibility: ClickHouse supports various data types and allows for custom functions, allowing for a lot of flexibility in data modeling and analysis.
- Monitoring: ClickHouse provides various monitoring tools like system.metrics, system.parts, system.merges and system.query_log tables and system metrics that can be used to monitor the cluster performance and troubleshoot issues.
How does a sparse index in ClickHouse benefit query performance?
Sparse index in ClickHouse is a feature that allows for creating an index on only a subset of the data, which can greatly benefit query performance in certain scenarios. Here are a few ways that sparse index can benefit query performance:
- Reduced index size: By only creating an index on a subset of the data, the index size is greatly reduced, which can improve query performance by reducing the amount of data that needs to be read and processed.
- Improved compression: Sparse index can improve compression ratios, as it only indexes the most frequently accessed data. This can improve query performance by reducing the amount of I/O required to process the query.
- Increased selectivity: Sparse index increases selectivity, as it only indexes the most frequently accessed data. This can improve query performance by reducing the amount of data that needs to be read and processed.
- Faster index creation: Sparse index can be created faster, as it only indexes a subset of the data. This can improve query performance by reducing the time required to create the index.
- Better memory usage: Sparse index can reduce the memory usage, as it only indexes a subset of the data. This can improve query performance by reducing the amount of memory required to process the query.
How can ChistaDATA help you build web-scale real-time data analytics using ClickHouse?
- Consulting – We are experts in building optimal, scalable (horizontally and vertically), highly available and fault-tolerant ClickHouse powered streaming data analytics platforms for planet-scale internet / mobile properties and the Internet of Things (IoT). Our elite-class consultants work very closely with your business and technology teams to build custom columnar database analytics solutions using ClickHouse.
- Database Architect services – We architect, engineer and deploy data analytics platforms for you. We will take care of your data analytics ecosystem so that you can focus on business.
- ClickHouse Enterprise Support – We have 24*7 enterprise-class support available for ClickHouse, Our support team will review and deliver guidance for your data analytics platforms architecture, SQL engineering, performance optimization, scalability, high availability and reliability.
- ClickHouse Training.
- Pay only for hours we have worked for you; This makes us affordable for startups and large corporations equally.
Why do successful companies work with ChistaDATA for ClickHouse Support and Managed Services?
- ChistaDATA provides full-stack ClickHouse Optimization. We deliver elite-class Consultative Support (24*7) and Managed Services for both on-premises ClickHouse infrastructure and Serverless/Cloud/ClickHouse DBaaS operations.
- ChistaDATA Server for ClickHouse (and all tools essential for Data Ops. @ Scale) will be Open Source (100% GPL forever) and free. We are committed to helping corporations in building Open Source ColumnStore for high-performance Data Analytics.
- Global Team available 24*7 for ClickHouse Consultative Support and Managed Services.
- Our team has built and managed Data Ops. Infrastructure of some of the largest internet properties. We know very well the best practices for building optimal, scalable, highly reliable and secured Database Infrastructure @ scale.
- Lean Team Culture: Startup-friendly and specialists in DevOps. and Automation for Database Systems Maintenance Operations.
- Transparent pricing and no hidden charges – We have both fixed-priced and flexible subscription plans.
- Based out of San Francisco Bay Area. But, we have global teams operating from 11 cities worldwide to deliver 24*7 Consultative Support and Managed Services for ClickHouse.
Conclusion
ColumnStores are well-suited for time-series data analytics because of their high performance, column pruning, compression, data organization, filter pushdown, time-series specific features and high-availability capabilities. These features allow for more efficient data retrieval and aggregation, resulting in faster query execution times and less I/O required.
To know more about ClickHouse ColumnStores, please do consider reading the below articles:
- Advantages of Column Stores for Real-time Analytics
- Comparing Columnar vs Row-based databases for Real-time Analytics
- Compression Techniques in Columnar Databases