Introduction
The amount of data stored in databases is increasing day by day. This increases the cost required for data storage and network access. Compression techniques are one of the commonly used methods to save storage space and speed up data access. This article aims to explain compression techniques for column store databases and the advantages of using compression on these databases.
Column-Store Compression
Traditionally, data is organized within a database block as a “row” where all column data for a given row is sequentially stored within a single data block. Having data from columns where different types of data are stored close together limits the amount of storage savings that can be achieved with compression technology. An alternative approach is to store in a ‘columnar’ format, where data is organized and stored by columns. Storing column data together with the same data type and similar characteristics dramatically increases the storage savings that can be achieved using compression.
One of the most commonly cited benefits of column-store is data compression. An intuitive argument for why columnar stores compress data well is that compression algorithms perform better on data with low information entropy (high locality of data values). It describes several compression algorithms that work particularly well with column-store databases and how to build query executors that work directly with compressed data. This allows the system to realize the I/O performance benefits of compression without paying the CPU cost of decompression.
Compression Techniques in Column-Store Databases
The main compression techniques used in “Column Oriented Databases” are explained below. All these methods are a form of lossless data compression that allows the original data to be perfectly reconstructed from the compressed data with no loss of information.
Dictionary Based Encoding
The purpose of dictionary-based encoding is to take advantage of recurring instruction sequences. The use of phrases is optimized through dictionary-based compression to increase compression efficiency. Dictionary-based compression methods offer quick decompression and efficient compression. The main idea is to use a dictionary to find the frequently occurring instruction sequences. In place of these recurring patterns, a codeword pointing to a particular dictionary index is used. The most common dictionary-based compression algorithms are Lempel-Ziv (LZ4), Brotli, Deflate, and Zstandard. In Fig 1, the compression mechanism of a dictionary-based encoding is shown.
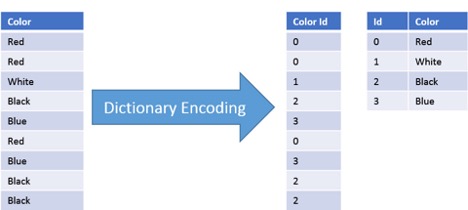
Fig 1 – Dictionary Based Encoding Example
Run Length Encoding
RLE is a simple and well-liked data compression algorithm. Run-length encoding reduces data size by substituting a compact singular representation for the same lengthy sequence in a column. It works well with columns that are sorted or that contain reasonable-sized runs of the same value. RLE is widely applicable in column-oriented databases because attributes are stored consecutively and runs of the same value are frequent. RLE example is shown in Fig 2.
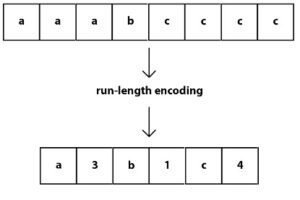
Fig 2 – Run Length Encoding Example
Hybrid Columnar Compression
Hybrid Columnar Compression technology is a new way of organizing data in database blocks. As the name suggests, this technology uses a combination of row and column methods to store data. This hybrid approach achieves the compression benefits of columnar storage while avoiding the performance penalties of pure columnar format.
Hybrid Columnar Compression takes a column vector for each column, compresses the column vector, and stores the column vector in a data block. This collection of data blocks is called a compression unit. The compression unit block contains all columns of a set of rows as shown in Fig 3.
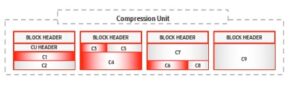
Fig 3 – HCC Logical Compression Unit
ClickHouse protocol supports LZ4 and ZSTD compression algorithms. LZ4 is faster but compresses less than ZSTD. You can choose what suits your case and workload.
Conclusion
In this research, some fairly simple techniques for improving database performance through data compression are outlined. These techniques not only reduce disk space requirements and I/O performance but also reduce memory requirements. Columnar databases are well suited for compression schemes that compress values for multiple rows at once. Compression schemes also improve CPU performance by allowing database operators to work directly with compressed data.
To learn more about compression in ClickHouse, read the following articles
- Data Compression Algorithms and Codecs in ClickHouse
- ClickHouse Performance: Achieving Maximum Data Compression
- Data Compression in ClickHouse: Algorithms for Top 5 Codecs
References
- Abadi, D. J., Boncz, P. B., & Harizopoulos, S. (2009). Column-oriented database systems. Proceedings of the VLDB Endowment, 2(2), 1664–1665.
- Boissier, M. (2021). Robust and Budget-Constrained Encoding Configurations for In-Memory Database Systems. Proceedings of the VLDB Endowment, 15(4), 780–793.
- Brief, T. (2022). Oracle Hybrid Columnar Compression, 1–11.
- Cwi, P. B. (2009). Column-Oriented Database Systems.
- Gupta, P., Mhedhbi, A., & Salihoglu, S. (2021). Columnar storage and list-based processing for graph database management systems. Proceedings of the VLDB Endowment, 14(11), 2491–2504.
- Raichand, P., & Aggarwal, R. R. (2013). a Short Survey of Data Compression Techniques for Column Oriented Databases. Journal of Global Research in Computer Science, 4(7), 2–5.
- Schäffner, S., & Liebald, S. (2018). Data Management in Distributed Systems. Seminar Innovative Internet Technologies and Mobile Communications, 113.
- Venkata Sai Sri Tikkireddy, L. (2019). Dictionary-based Compression Algorithms in Mobile Packet Core, (October).
- https://www.microsoftpressstore.com/articles/article.aspx?p=2449192&seqNum=3
- https://api.video/what-is/run-length-encoding