Designing ClickHouse for Mixed Workloads: Separating OLTP-Style Inserts from Heavy OLAP Queries in ClickHouse
In today’s data-driven landscape, organizations increasingly need databases that can handle both transactional and analytical workloads efficiently. ClickHouse, primarily known as an OLAP (Online Analytical Processing) database, has evolved to support mixed workloads that combine OLTP-style (Online Transaction Processing) inserts with heavy analytical queries. This comprehensive guide explores proven strategies for designing ClickHouse deployments that excel at both real-time data ingestion and complex analytics.
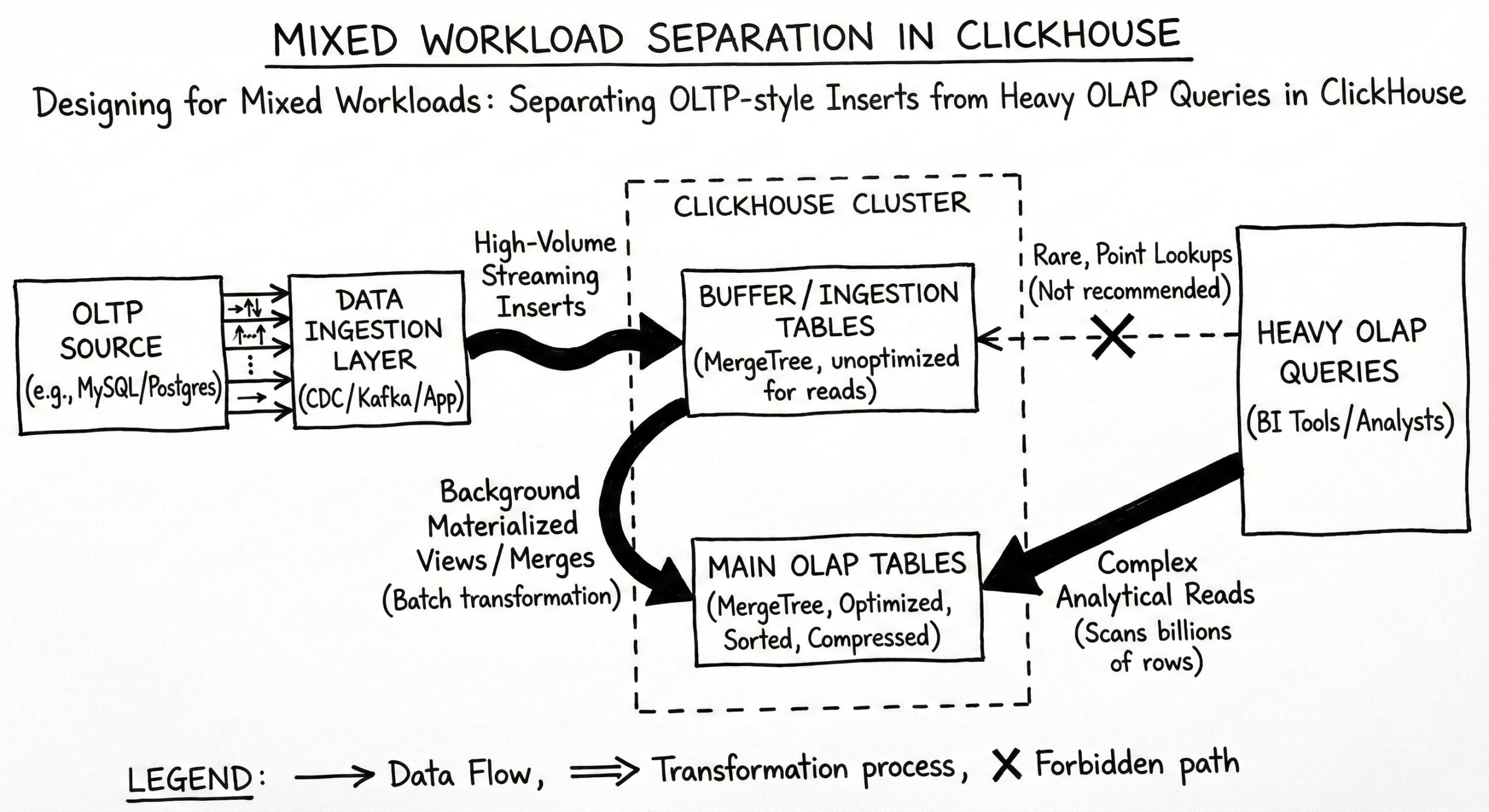
Understanding the Mixed Workload Challenge
Mixed workloads present unique challenges that traditional database architectures struggle to address. OLTP systems serve as the authoritative source of operational data, where real-time transactions are processed, and data is constantly updated. However, analytical workloads, which involve complex queries on large datasets, are best handled by OLAP systems. The challenge lies in creating a unified architecture that can efficiently handle both patterns without compromising performance.
In practice OLAP and OLTP are not categories, it’s more like a spectrum. Most real systems usually focus on one of them but provide some solutions or workarounds if the opposite kind of workload is also desired. This reality has led to the development of sophisticated techniques within ClickHouse to support mixed workload scenarios effectively.
ClickHouse’s Approach to Mixed Workloads
ClickHouse addresses mixed workloads through several key architectural innovations. ClickHouse is designed to handle high concurrency workloads. It is frequently used in applications where organizations want to provide real-time analysis, evaluation, and querying. The database achieves this through a combination of specialized table engines, intelligent buffering mechanisms, and advanced query optimization techniques.
Recent developments have further enhanced ClickHouse’s mixed workload capabilities. The goal is simple: let teams run transactional and analytical workloads side by side without stitching together multiple systems or maintaining complex pipelines. This launch reflects a pattern we have seen repeatedly in production. PostgreSQL remains the system of record, while ClickHouse handles analytics at scale.
Core Architectural Strategies
1. Asynchronous Insert Processing
One of the most effective strategies for handling OLTP-style workloads in ClickHouse is leveraging asynchronous inserts. When enabled (1), inserts are buffered and only written to disk once one of the flush conditions is met: (1) the buffer reaches a specified size (async_insert_max_data_size) (2) a time threshold elapses (async_insert_busy_timeout_ms) or (3) a maximum number of insert queries accumulate (async_insert_max_query_number). This batching process is invisible to clients and helps ClickHouse efficiently merge insert traffic from multiple sources.
With asynchronous inserts enabled, ClickHouse: (1) receives an insert query asynchronously. (2) writes the query’s data into an in-memory buffer first. (3) sorts and writes the data as a part to the database storage, only when the next buffer flush takes place. This approach significantly improves insert performance while maintaining data consistency.
2. Specialized Table Engines for Mixed Workloads
ReplacingMergeTree for OLTP-Style Operations
The ReplacingMergeTree table engine allows update operations to be applied to rows, without needing to use inefficient ALTER or DELETE statements, by offering the ability for you to insert multiple copies of the same row and denote one as the latest version. This makes it ideal for scenarios where you need to handle updates and upserts in an OLTP-style manner.
When using ReplacingMergeTree, we recommend users partition their table according to best practices, provided you can ensure this partitioning key does not change for a row. This will ensure updates pertaining to the same row will be sent to the same ClickHouse partition.
Buffer Tables for High-Frequency Inserts
For extremely high-frequency insert scenarios, ClickHouse provides Buffer tables. When adding data to a Buffer table, one of the buffers is locked. This causes delays if a read operation is simultaneously being performed from the table. While Buffer tables require careful configuration, they can be effective for specific use cases where insert throughput is critical.
3. Materialized Views for Real-Time Data Transformation
Incremental Materialized Views (Materialized Views) allow you to shift the cost of computation from query time to insert time, resulting in faster SELECT queries. Unlike in transactional databases like Postgres, a ClickHouse materialized view is just a trigger that runs a query on blocks of data as they are inserted into a table.
Consider insert volume and frequency. JOINs work well in moderate insert workloads. For high-throughput ingestion, consider using staging tables, pre-joins, or other approaches such as Dictionaries and Refreshable Materialized Views. This flexibility allows you to optimize the balance between insert performance and query speed based on your specific workload characteristics.
Performance Optimization and Resource Management
Workload Scheduling and Resource Isolation
ClickHouse provides sophisticated workload scheduling capabilities to manage mixed workloads effectively. When ClickHouse execute multiple queries simultaneously, they may be using shared resources (e.g. disks and CPU cores). Scheduling constraints and policies can be applied to regulate how resources are utilized and shared between different workloads.
This resource management becomes crucial when separating OLTP-style inserts from heavy OLAP queries, ensuring that analytical workloads don’t interfere with real-time data ingestion performance.
Query Parallelism and Optimization
When ClickHouse runs an aggregation query with a filter on the table’s primary key, it loads the primary index into memory to identify which granules need to be processed, and which can be safely skipped. Understanding this execution model is crucial for optimizing mixed workloads, as it allows you to design schemas that support both efficient inserts and fast analytical queries.
Scaling Strategies for Mixed Workloads
Read-Write Separation
Read-write separation divides database operations into two categories: read operations (SELECT queries) and write operations (INSERT, UPDATE, DELETE queries). This seemingly simple division brings forth an array of advantages. In ClickHouse deployments, this separation can be implemented through cluster configurations that route different workload types to optimized nodes.
Scaling ClickHouse horizontally while optimizing the split between read and write operations is a multi-step process that involves setting up a cluster with sharded and replicated tables. This approach allows organizations to scale insert capacity independently from analytical query performance.
Distributed Tables and Sharding
Tables with Distributed engine do not store any data of their own, but allow distributed query processing on multiple servers. Reading is automatically parallelized. During a read, the table indexes on remote servers are used if they exist.
Typically, a distributed table (often per server) provides a unified view of the full dataset. It doesn’t store data itself but forwards SELECT queries to all shards, assembles the results, and routes INSERTS to distribute data evenly. This architecture enables effective workload separation by distributing both insert and query loads across multiple nodes.
Real-World Implementation Patterns
Case Study: GitLab’s Analytics Transformation
With ClickHouse, GitLab’s analytics stack was transforming. Features like Contribution Analytics now deliver sub-second performance on datasets. The feature surfaces insights into team activity and individual performance, supporting use cases like workload balancing, identifying high performers or those needing support, assessing collaboration patterns, spotting training needs, and enriching retrospectives with real data.
This transformation demonstrates how proper mixed workload design can deliver both real-time operational insights and complex analytical capabilities within a single system.
Hybrid Architecture Patterns
Analytics workloads (reporting, aggregations, time-series) → Use ClickHouse with application orchestration. Hybrid architecture → Use both! Stream transactional data from OLTP to ClickHouse for analytics. This pattern has become increasingly common, where organizations maintain traditional OLTP systems for transactional integrity while leveraging ClickHouse for analytical workloads.
Best Practices and Recommendations
1. Schema Design Considerations
When designing for mixed workloads, consider partitioning strategies that support both insert patterns and analytical queries. MergeTree-family table engines are designed for high data ingest rates and huge data volumes. Insert operations create table parts which are merged by a background process with other table parts.
2. Monitoring and Observability
Implement comprehensive monitoring for both insert performance and query latency. The following diagram visualizes this: monitoring_async_inserts_02.png When ClickHouse receives an asynchronous insert query, then the query’s data is immediately written into an in-memory buffer first. Understanding these internal processes is crucial for optimizing mixed workload performance.
3. Configuration Optimization
Tune async insert parameters based on your specific workload characteristics. Balance between insert latency requirements and analytical query performance by adjusting buffer sizes, timeout values, and flush conditions.
Conclusion
Designing ClickHouse deployments for mixed workloads requires a deep understanding of both OLTP and OLAP patterns, combined with careful architectural planning. By leveraging asynchronous inserts, specialized table engines like ReplacingMergeTree, materialized views, and distributed architectures, organizations can build systems that excel at both real-time data ingestion and complex analytics.
The key to success lies in understanding your specific workload characteristics and choosing the right combination of ClickHouse features to optimize for both insert performance and analytical query speed. As demonstrated by companies like GitLab, proper implementation of these strategies can transform analytical capabilities while maintaining operational efficiency.
Real-time OLAP systems like ClickHouse allow this analysis to happen as data is ingested in real-time, making it possible to build truly unified data platforms that serve both operational and analytical needs without compromise. The future of data architecture increasingly points toward these hybrid approaches, where the artificial boundaries between OLTP and OLAP systems dissolve in favor of more flexible, unified solutions.
Further Reading
- ClickHouse Consulting
- ClickHouse Support
- ClickHouse Managed Services
- Data Analytics and Data Engineering
- ChistaDATA University
You might also like:
- ChistaDATA Cloud DBAAS : Performing data exploration and visualisation using Apache Superset – Part 1
- An Introduction to Time-Series Databases: Powering Modern Data-Driven Applications
- ClickHouse Winter 2024 Release – v24.2
- How are Regular Expressions (RegEx) implemented in ClickHouse?
- ClickHouse vs Hadoop for Real-time Analytics


