ClickHouse Storage Tiering Best Practices: Moving Data Between Hot and Cold Storage with TTL
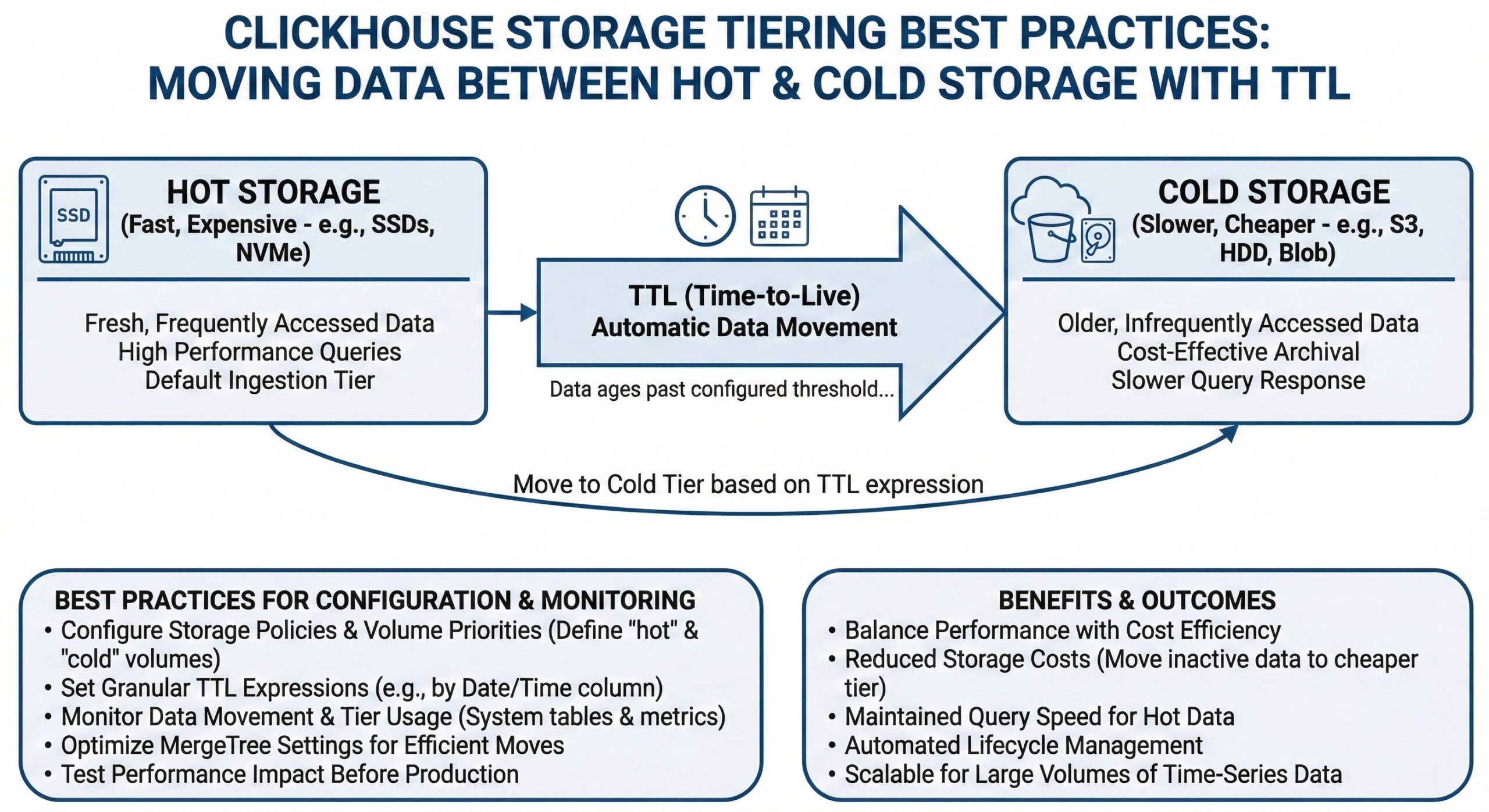
Efficient data management is critical for modern analytical databases, especially when dealing with large volumes of time-series or event-driven data. ClickHouse, known for its high-performance analytics capabilities, offers a powerful feature called Time-to-Live (TTL) that enables automatic storage tiering—the process of moving data between fast, expensive storage (like SSDs) and slower, cheaper storage (like S3 or HDDs). This approach allows organizations to balance query performance with cost efficiency, particularly in cloud and on-premise deployments.
In this guide, we’ll explore best practices for configuring storage policies, setting volume priorities, monitoring data movement, and optimizing performance while reducing costs using TTL-based storage tiering in ClickHouse.
What Is Storage Tiering in ClickHouse?
ClickHouse supports multi-volume storage, allowing you to define different storage tiers such as:
- Hot storage: Fast local SSDs for recently accessed, frequently queried data.
- Cold storage: Slower, cost-effective options like HDDs or remote object storage (e.g., AWS S3, Google Cloud Storage).
Using TTL expressions, ClickHouse can automatically move data from hot to cold storage after a specified period, or even delete it entirely when it’s no longer needed. This capability is essential for managing data lifecycle and reducing infrastructure costs without compromising performance for recent data.
Configuring Storage Policies
Storage policies are defined in the config.xml file of your ClickHouse server. A policy consists of one or more volumes, each made up of multiple disks. Here’s an example configuration:
<storage_configuration>
<disks>
<ssd1>
<type>local</type>
<path>/var/lib/clickhouse/ssd/</path>
</ssd1>
<hdd1>
<type>local</type>
<path>/var/lib/clickhouse/hdd/</path>
</hdd1>
<s3>
<type>s3</type>
<endpoint><https://s3.amazonaws.com/your-bucket/clickhouse/></endpoint>
<access_key_id>your-access-key</access_key_id>
<secret_access_key>your-secret-key</secret_access_key>
</s3>
</disks>
<policies>
<tiered>
<volumes>
<hot>
<disk>ssd1</disk>
</hot>
<cold>
<disk>hdd1</disk>
</cold>
<frozen>
<disk>s3</disk>
</frozen>
</volumes>
</tiered>
</policies>
</storage_configuration>
This setup defines three tiers:
- hot: For new data (fast SSD).
- cold: For older data moved from SSD (HDD).
- frozen: For archival data stored in S3.
Each volume can have priority settings, determining the order in which ClickHouse uses them.
Setting Up TTL Rules for Data Movement
Once the storage policy is configured, you can apply TTL rules at the table level. For example:
CREATE TABLE sensor_data (
timestamp DateTime,
device_id Int64,
temperature Float32
) ENGINE = MergeTree
ORDER BY (device_id, timestamp)
PARTITION BY toYYYYMM(timestamp)
TTL timestamp + INTERVAL 30 DAY TO VOLUME 'cold',
timestamp + INTERVAL 90 DAY TO VOLUME 'frozen',
timestamp + INTERVAL 365 DAY DELETE;
This TTL definition:
- Moves data to the cold volume (HDD) after 30 days.
- Moves data to the frozen volume (S3) after 90 days.
- Deletes data entirely after 1 year.
You can also use TO DISK instead of TO VOLUME if you want to target a specific disk rather than a tier.
✅ Best Practice: Always align TTL intervals with your data access patterns. Frequently queried data should remain on fast storage, while infrequently accessed historical data can be moved to S3.
Monitoring Data Movement
To ensure your tiering strategy works as expected, monitor data distribution across volumes:
SELECT
table,
partition,
name AS part_name,
disk_name,
bytes_on_disk
FROM system.parts
WHERE table = 'sensor_data'
ORDER BY modification_time;
Additionally, check system logs for background merges and TTL task execution. ClickHouse logs every data movement operation, helping you troubleshoot delays or failures.
Use tools like Prometheus and Grafana to visualize disk usage, query latency, and data movement trends over time. Monitoring helps detect bottlenecks—especially during heavy write loads or concurrent queries on S3-backed data.
Performance vs. Cost Trade-offs
While S3 offers low-cost, scalable storage, querying data from S3 is slower than from local SSDs. To mitigate performance impact:
- Cache frequently accessed cold data: ClickHouse has built-in caches for metadata, mark files, and even uncompressed data blocks. Leverage these to speed up queries on S3-stored data.
- Use projection or materialized views: Pre-aggregate historical data to reduce scan size.
- Optimize S3 read performance: Use larger instance types with higher network bandwidth, enable compression, and consider using ClickHouse’s S3-backed virtual warehouses in cloud environments.
💡 Pro Tip: In cloud deployments, combine S3 with ClickHouse’s separation of compute and storage architecture to scale compute independently while keeping data centralized.
Cloud vs. On-Premise Considerations
Cloud Deployments (AWS, GCP, Azure)
- Use S3, GCS, or Blob Storage as cold/frozen tiers.
- Integrate with IAM roles for secure access.
- Enable server-side encryption and lifecycle policies on the object store.
- Consider using ClickHouse Cloud for managed tiering and automated operations.
On-Premise Deployments
- Use local HDDs or NAS systems as cold storage.
- Ensure sufficient network bandwidth between ClickHouse nodes and storage.
- Monitor disk health and I/O latency to prevent query degradation.
Conclusion
ClickHouse’s TTL-based storage tiering is a game-changer for organizations looking to optimize both performance and cost. By intelligently moving data between hot (SSD), cold (HDD), and frozen (S3) storage, you can maintain fast query response times for recent data while archiving older data affordably.
Key Takeaways:
- Define clear storage policies in config.xml.
- Use TTL expressions to automate data movement and deletion.
- Monitor data placement via system.parts and logs.
- Balance performance and cost by caching and optimizing queries on cold data.
- Adapt strategies based on deployment type—cloud or on-premise.
With proper configuration and monitoring, ClickHouse becomes not just a high-speed analytics engine, but also a smart, self-managing data warehouse.
References
[^1]: Amplifying ClickHouse® Capacity with Multi-Volume Storage (Part 2)
[^2]: GitHub – mrankitsinghal/clickhouse-s3-setup: ClickHouse tiered storage …
[^3]: Optimizing for S3 Insert and Read Performance – ClickHouse Docs
[^4]: Building a Distributed Cache for S3
[^5]: Separation of storage and compute – ClickHouse Docs
[^6]: Managing data | ClickHouse Docs
[^7]: ClickHouse® MergeTree on S3 – Administrative Best Practices – Altinity
Further Reading
- Troubleshooting Disk Space in ClickHouse
- Essential ClickHouse Metrics
- Boosting Materialized View Performance
- PREWHERE vs WHERE in ClickHouse Queries
- Understanding ClickHouse Wait Events