Designing ClickHouse Schemas for 1B+ Row Tables: Mastering Engines, Primary Keys, and Partitioning for Real-Time Analytics
When dealing with billion-row datasets in real-time analytics, schema design becomes the cornerstone of performance. ClickHouse, with its columnar architecture and sophisticated optimization features, excels at handling massive datasets, but only when properly configured. This comprehensive guide explores the critical decisions around table engines, primary key selection, and partitioning strategies that can make the difference between millisecond and second-long queries.
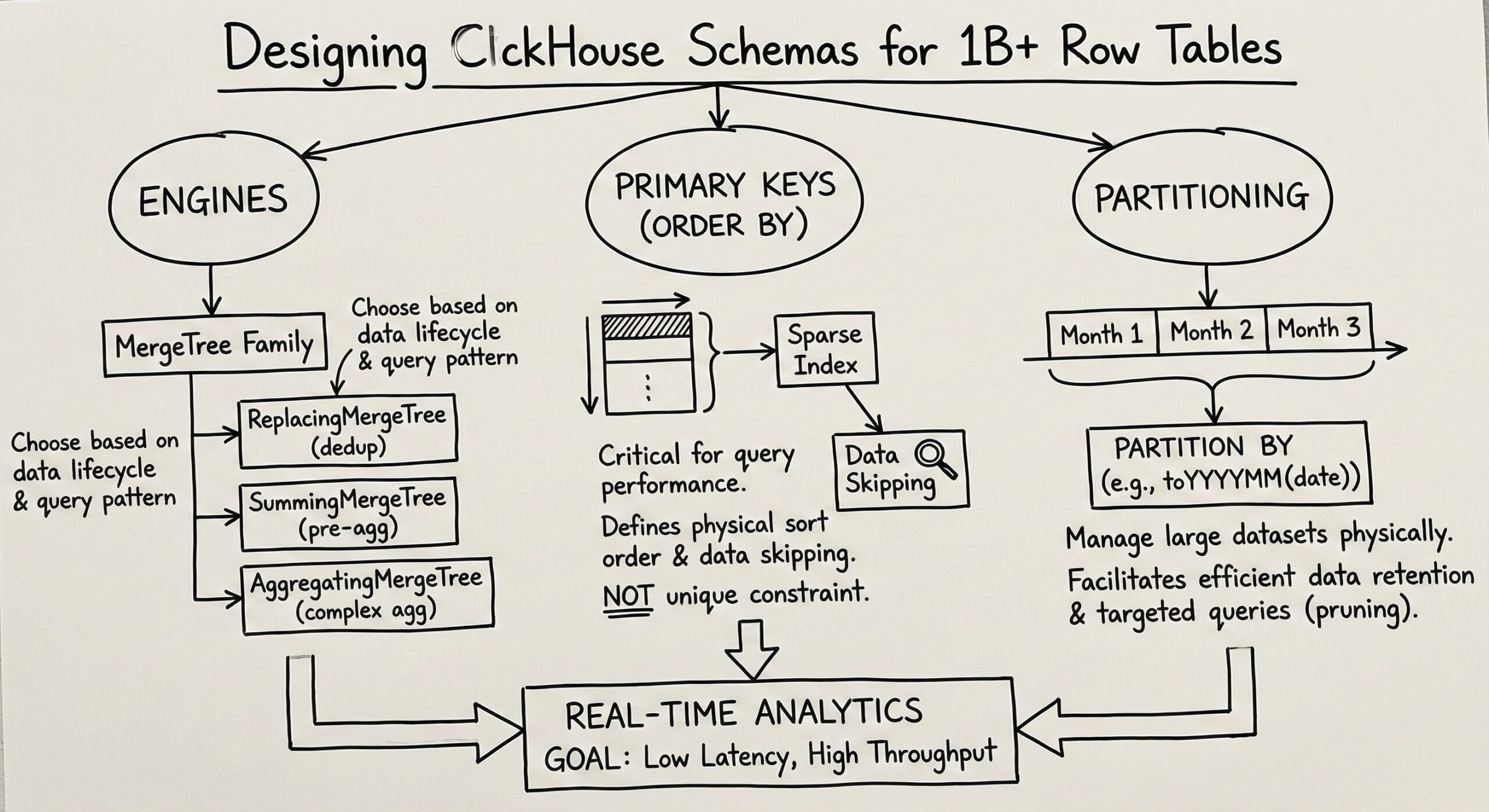
Understanding ClickHouse’s MergeTree Engine Family
The foundation of any high-performance ClickHouse deployment lies in selecting the appropriate table engine. The MergeTree family represents the most robust and commonly used engines for large-scale analytics workloads.
Core MergeTree Engine
The standard MergeTree engine serves as the workhorse for most billion-row scenarios. It’s specifically designed for high data ingest rates and large data volumes, making it ideal for real-time analytics. Key characteristics include:
- Immutable parts storage: Data is stored as immutable parts that are periodically merged
- Sparse primary indexing: Creates efficient indexes every 8,192 rows or 10MB of data
- Columnar compression: Optimizes storage and query performance
- Parallel processing: Supports concurrent reads and writes
ReplacingMergeTree for Upsert Scenarios
For real-time analytics requiring data updates, ReplacingMergeTree provides an elegant solution. This engine allows multiple copies of the same row with version control, automatically keeping the latest version during merges. It’s particularly valuable for:
- User behavior tracking where events may be updated
- IoT sensor data with late-arriving corrections
- Financial transactions requiring audit trails
The engine maintains data integrity while avoiding the performance penalties of traditional UPDATE operations.
Specialized Engines for Specific Use Cases
AggregatingMergeTree excels when pre-aggregating data during ingestion, perfect for real-time dashboards requiring instant aggregation results. This engine automatically merges rows with identical primary keys using specified aggregate functions, dramatically reducing storage requirements and query times for analytical workloads.
Primary Key Design: The Performance Multiplier
Primary key selection in ClickHouse differs fundamentally from traditional OLTP databases. Rather than ensuring uniqueness, ClickHouse primary keys determine data ordering and create sparse indexes that can improve query performance by 100× or more.
Core Principles for Primary Key Selection
1. Prioritize Query Filter Columns
The most critical rule is prioritizing columns frequently used in WHERE clauses that exclude large numbers of rows. For a user analytics table, this might mean:
CREATE TABLE user_events (
user_id UInt64,
event_date Date,
event_type Enum8('click' = 1, 'view' = 2, 'purchase' = 3),
session_id String,
timestamp DateTime
) ENGINE = MergeTree()
ORDER BY (user_id, event_date, event_type)
This ordering optimizes for common queries filtering by user, date ranges, and event types.
2. Leverage Data Correlation
Columns highly correlated with other data improve compression ratios and memory efficiency during GROUP BY and ORDER BY operations. Geographic data, for example, benefits from ordering by region, then city, then postal code.
3. Optimal Key Length
While ClickHouse supports long primary keys, 4-5 components typically provide optimal performance. Each additional column in the primary key improves filtering for that dimension but increases index size and memory usage.
Real-World Primary Key Example
Consider a posts table with billions of rows:
CREATE TABLE posts_optimized (
Id Int32,
PostTypeId Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3),
CreationDate DateTime,
UserId UInt64,
Score Int32
) ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), UserId)
This design prioritizes:
- PostTypeId (cardinality of 8) for efficient type-based filtering
- toDate(CreationDate) for time-range queries with reduced index size
- UserId for user-specific analytics
This optimization can reduce data scanning by orders of magnitude, achieving 4× performance improvements over unoptimized schemas1.
Partitioning Strategies for Real-Time Analytics
Partitioning in ClickHouse serves primarily as a data management technique rather than a query optimization tool. However, when properly implemented, it significantly enhances real-time analytics workflows.
Time-Based Partitioning for Analytics Workloads
Real-time analytics typically benefit from time-based partitioning:
CREATE TABLE real_time_events (
timestamp DateTime,
user_id UInt64,
event_data String,
metric_value Float64
) ENGINE = MergeTree()
PARTITION BY toStartOfMonth(timestamp)
ORDER BY (timestamp, user_id)
This approach enables:
- Efficient data retention: Drop old partitions without scanning entire tables
- Parallel processing: Queries can process multiple partitions simultaneously
- Optimized ingestion: New data writes to current partition only
Low-Cardinality Partitioning Keys
The cardinal rule for partitioning is maintaining low cardinality (fewer than 100-1,000 distinct values). High-cardinality partitioning leads to:
- Too many parts errors: ClickHouse limits parts per partition
- Reduced merge efficiency: Parts don’t merge across partitions
- Increased metadata overhead: Each partition requires separate management
Partition Size Optimization
Optimal partition sizes for billion-row tables typically range from 10-100 million rows per partition. This balance ensures:
- Efficient parallel processing
- Manageable metadata overhead
- Effective compression ratios
- Reasonable merge operation times
Advanced Optimization Techniques
Data Skipping Indexes
Beyond primary keys, data skipping indexes provide additional query acceleration. These indexes help ClickHouse skip entire data blocks that cannot contain matching values:
ALTER TABLE events ADD INDEX user_bloom_idx user_id TYPE bloom_filter GRANULARITY 1; ALTER TABLE events ADD INDEX event_minmax_idx event_timestamp TYPE minmax GRANULARITY 3;
Bloom filter indexes excel for high-cardinality columns with equality filters, while MinMax indexes optimize range queries on numeric and date columns.
Memory and Storage Optimization
For billion-row tables, memory management becomes critical:
1. Compression Optimization
- Use appropriate codecs for different data types
- Order data to maximize compression ratios
- Consider dictionary encoding for repeated strings
2. Storage Tiering
- Implement TTL policies for automatic data lifecycle management
- Use multiple storage devices for hot/cold data separation
- Configure appropriate merge policies for workload patterns
Real-World Performance Results
Companies implementing these strategies report dramatic improvements. HighLevel achieved an 88% reduction in storage and P99 queries dropping from 6+ seconds to less than 200 milliseconds after optimizing their ClickHouse schema design. Similarly, ClickHouse consistently outperformed other databases in billion-row benchmarks, demonstrating the impact of proper schema design.
Monitoring and Continuous Optimization
Effective schema design requires ongoing monitoring and optimization:
1. Query Performance Analysis
Use system.query_log to analyze query patterns and identify optimization opportunities.
2. Part Management
Monitor part counts and merge operations to ensure healthy table maintenance.
3. Index Effectiveness
Regularly evaluate data skipping index usage and effectiveness through system tables.
Best Practices for Production Deployments
Schema Evolution Strategy
Design schemas with evolution in mind:
- Use nullable columns for future additions
- Implement versioning strategies for breaking changes
- Plan for data migration scenarios
Testing and Validation
Before deploying billion-row schemas:
- Test with representative data volumes
- Validate query performance across expected access patterns
- Benchmark different engine and key combinations
Operational Considerations
- Implement proper backup and recovery procedures
- Plan for cluster scaling scenarios
- Monitor resource utilization patterns
Conclusion
Designing ClickHouse schemas for billion-row real-time analytics requires careful consideration of engine selection, primary key design, and partitioning strategies. The MergeTree engine family provides robust foundations, while thoughtful primary key selection can deliver 100× performance improvements. Partitioning serves data management needs with low-cardinality keys, and data skipping indexes provide additional optimization opportunities.
Success lies in understanding your specific query patterns, implementing appropriate optimization techniques, and continuously monitoring performance. With proper schema design, ClickHouse can deliver sub-second query performance on billion-row datasets, enabling true real-time analytics at scale.
The key is starting with solid fundamentals—choosing the right engine, designing effective primary keys, and implementing appropriate partitioning—then iteratively optimizing based on real-world usage patterns. This approach ensures your ClickHouse deployment can scale efficiently while maintaining the performance characteristics essential for modern real-time analytics workloads.