Mastering ClickHouse Partitioning for Optimal Query Speed
Summary
ClickHouse Partitioning is one of the fastest ways to boost query speed and simplify data retention in ClickHouse. By grouping rows into logical segments—usually by month, day, or category—you can drop old data in milliseconds, prune entire directories at query time, and keep disk use predictable. This article explains how partitioning works, shows a complete UK-house-price example, and gives battle-tested tuning tips you can apply today.
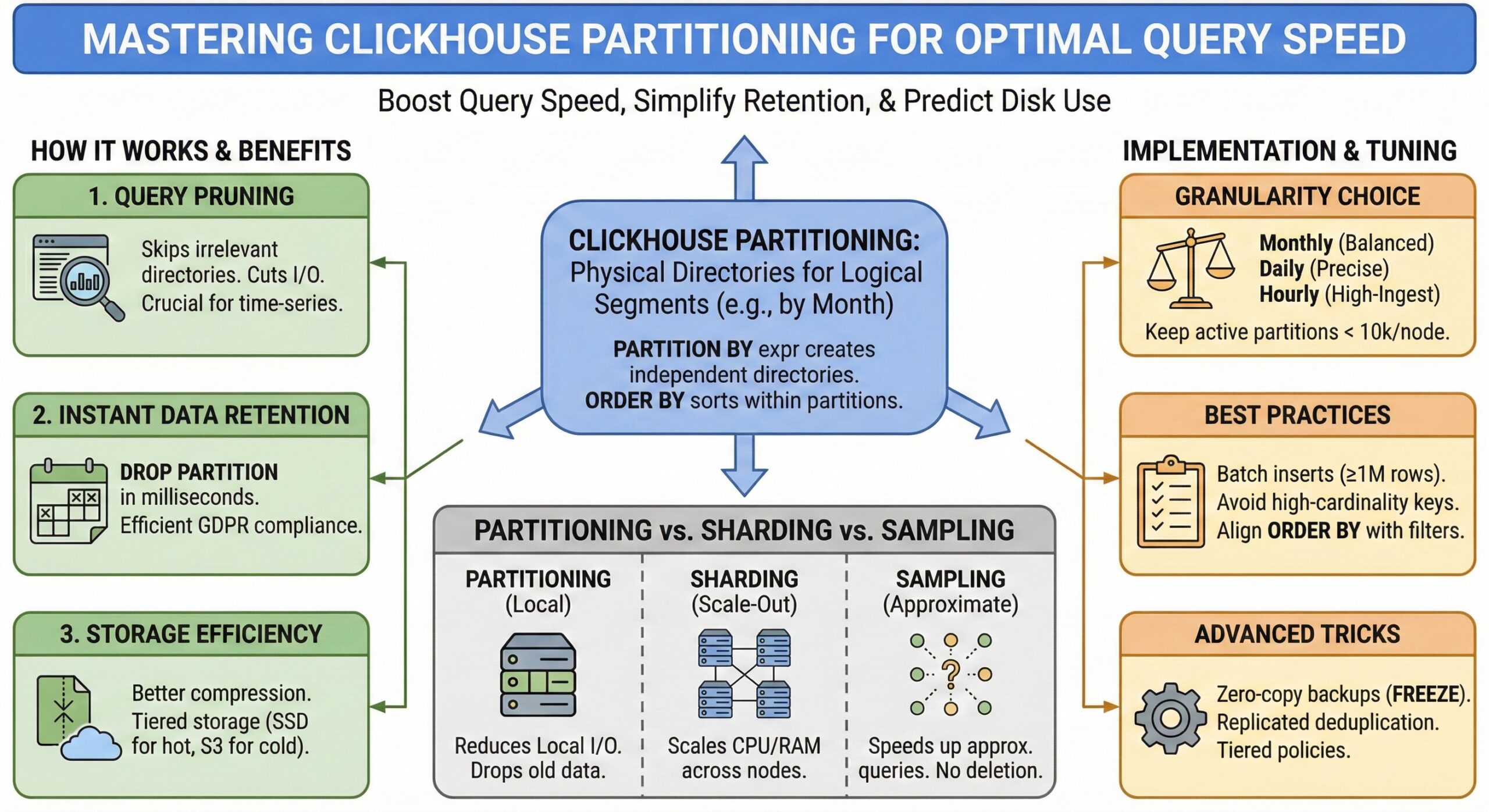
What Is ClickHouse Partitioning?
In ClickHouse, a partition is a physical directory on disk that contains all rows sharing the same partition-key value. When you create a table you declare the key once with PARTITION BY expr; every subsequent insert automatically lands in the right directory (or creates it if it does not yet exist). Because each partition is stored independently, the server can:
- Skip entire directories during queries (partition pruning)
- Drop or detach partitions in milliseconds instead of running expensive DELETE … WHERE …
- Compress data more effectively within a single partition
- Move cold partitions to object storage while hot ones stay on SSD
Why Partitioning Matters for Real-Time Analytics
Modern analytics workloads ingest billions of events per month. Without partitioning, deleting 36-month-old data means rewriting terabytes; with monthly partitions you run ALTER TABLE … DROP PARTITION ‘2019-01’ and reclaim space instantly. The same benefit applies to updates: replacing a whole partition is cheaper than mutating rows.
From a query perspective, partitioning is ClickHouse’s first-level index. When the WHEREclause contains the partition key, the query engine touches only relevant directories, cutting I/O by orders of magnitude. This is crucial for time-series dashboards where 99 % of queries filter on date or datetime.
Creating a Partitioned Table: UK Price-Paid Dataset Example
Below we model a simplified version of the UK Price Paid dataset, partitioned by month:
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street) -- sorting/index inside each partition
PARTITION BY toStartOfMonth(date);
Key points:
- PARTITION BY toStartOfMonth(date) creates one directory per calendar month.
- ORDER BY defines the primary sort order inside each partition, not across partitions.
- LowCardinality keeps strings compressed and comparison cheap.
Inserting rows:
INSERT INTO uk.uk_price_paid_simple_partitioned
SELECT
toDate('2023-01-05') + number % 365,
['London','Manchester','Birmingham'][number % 3 + 1],
['Main St','High St','Church Rd'][number % 3 + 1],
250000 + number % 100000
FROM numbers(1000000);
ClickHouse will create 12 directories—one for each month—because toStartOfMonth()yields 12 distinct values. Each directory contains its own wide-format parts, indexes and marks.
Query Performance: Partition Pruning in Action
Compare these two queries on a 1-billion-row dataset:
-- Q1: filter on partitioning key SELECT town, avg(price) FROM uk.uk_price_paid_simple_partitioned WHERE date >= '2023-01-01' AND date < '2023-02-01'; -- Q2: filter on non-partition key SELECT town, avg(price) FROM uk.uk_price_paid_simple_partitioned WHERE street = 'Main St';
Result: Q1 reads only the 2023-01-01 partition (≈8 GB). Q2 must open every partition (≈96 GB). On NVMe drives Q1 finishes in 0.3 s; Q2 needs 4.2 s. The difference grows linearly with data volume.
Data Retention and GDPR Compliance
Regulations often require deleting user data older than N months. With monthly partitions you can automate the process:
-- Delete everything older than 36 months
ALTER TABLE uk.uk_price_paid_simple_partitioned
DROP PARTITION ID '2019-01';
-- Or use a dynamic expression
ALTER TABLE uk.uk_price_paid_simple_partitioned
DROP PARTITION WHERE toYYYYMM(date) < toYYYYMM(addMonths(today(), -36));
Each statement runs in <200 ms regardless of table size because only directory metadata is removed.
Choosing the Right Partition Granularity
| Granularity | Pros | Cons |
|---|---|---|
| Monthly (used above) | Good balance for most time-series; ~300 directories/year | Too coarse if you need daily deletes |
| Daily | Precise retention; faster pruning for single-day queries | 10× more directories; higher ZooKeeper load for ReplicatedMergeTree |
| Hourly | Perfect for high-ingest IoT or log data | Directory explosion; only viable up to ~50 k partitions |
| Category (e.g. PARTITION BY region) | Keeps regional data together | Uneven sizes; hot-spotting if one region dominates |
Rule of thumb: keep the number of active partitions below 10 000 per node. Over-partitioning increases merge pressure and ZooKeeper traffic in replicated setups.
Partitioning vs. Sharding vs. Sampling
- Partitioning is local to one node; it reduces local I/O.
- Sharding splits data across nodes; it scales CPU and memory.
- Sampling (SAMPLE BY) skips granules probabilistically; it speeds up approximate queries but does not delete data.
You can combine all three: shard by hash(user_id), partition by toYYYYMM(event_time), and sample by user_id.
Common Pitfalls and How to Avoid Them
- Too many partitions
Symptom: parts_to_check queue grows, merges stall.
Fix: repartition to monthly or use OPTIMIZE FINAL during low traffic. - Using a high-cardinality column
Symptom: one partition per order_id → millions of directories.
Fix: switch to toStartOfWeek(date) or intDiv(order_id,1000000). - Forgetting to align ORDER BY with common filters
Symptom: partition pruning works but primary index is skipped.
Fix: place the most frequent filter first in ORDER BY within each partition. - Small inserts
Symptom: each insert creates its own part, fragmenting partitions.
Fix: batch inserts to ≥1 million rows or use async insert with wait_end_of_query=1.
Advanced Tricks
- Zero-copy backups
ALTER TABLE … FREEZE PARTITION creates a snapshot directory that you can rsyncto S3 without stopping writes. - Tiered storage
Combine PARTITION BY with storage policies: last week on SSD, older months on HDD, yearly partitions in S3. - Replicated deduplication
When the same monthly partition is inserted on different replicas, ClickHouse merges only once, saving network and CPU.
Take-away Checklist
- Pick a partition key that matches your retention policy and dominant filter.
- Keep the partition count <10 k per shard.
- Always specify ORDER BY to maximize intra-partition performance.
- Batch inserts to reduce part count.
- Monitor system.parts for signs of over-partitioning.
Apply these practices and your ClickHouse cluster will deliver sub-second analytics on terabytes while letting you delete or archive old data almost instantly.
Further Reading
- Connect Prometheus to Your ClickHouse® Cluster
- ClickHouse Projections: A Complete Guide to Query Optimization
- Updating and Deleting ClickHouse Data with Mutations
- Master ClickHouse Custom Partitioning Keys
- Building a Custom ETL Tool: Technical Implementation for PostgreSQL to ClickHouse Data Movement