Introduction
Is 90% availability good? Why is high availability important? What does that mean for a business in plain terms? Let’s dive into them.
What is High Availability (HA)?
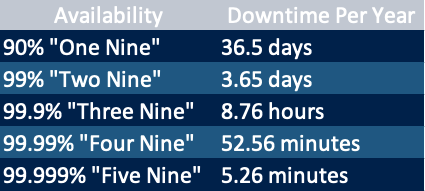
Business critical databases require minimal downtime and continuous availability. Because businesses and enterprises rely on the availability and accessibility of their data each passing day. Consequently, the definition of high availability solutions is becoming more important nowadays. As might be expected, high availability is a component that eliminates a single point of failure to operate continuously or uptime for a designated period of time. Contrary to popular belief, high availability solutions do not guarantee 100% uptime. Still, if a database is available, 99.999% (as known as five-nines availability) of the time could be considered a difficult-to-achieve goal. Eventually, getting an environment closer to five-nines availability could lower your risk of lost revenue and unhappy customers.
Determine your High Availability (HA) need
Depending on the database type, high availability measures will be different. For example, a database of a telecom industry that could have five nines (99.999%) availability per year is called an industry standard however, the uncritical databases may have two nines (99%) availability could be normal, which equals 4-day downtime per year, approximately.
High Availability options depend on many factors. How many users are affected, how much database size, how many databases should be considered, etc. Using these factors is useful for determining RTO and RPO values while creating an architecture.
What’s the role of RTO in High Availability (HA)?
Recovery Time Objective specifies the maximum tolerable duration of planned or unplanned outages. OLTP databases especially have the lowest RTOs. Scheduled downtime is required for hardware and software maintenance. However, unplanned outages should also be considered.
What’s the role of RPO in High Availability (HA)?
Recovery Point Objective specifies the maximum amount of data loss that could be tolerated in the event of a failure. While this period can be up to 24 hours for an OLAP environment that receives bulk data once a day. However, the RPO value should be close to zero for an OLTP database like trading platforms or web applications database.
A more synchronous database means more ready for switchover/failover operations in disaster scenarios. In order to reduce risk, data replication could be synchronous across the local area network (LAN). Thus, real-time solutions can be even more useful in critical databases’ toughest RPO and RTO conditions. On the other hand, data replication could be asynchronous to avoid negatively impacting throughput performance in geographically distributed data centers (WAN). It is necessary to determine how much budget should be allocated to get the best RTO and RPO results.
How is ClickHouse beneficial for High Availability (HA)?
ClickHouse has plenty of features to improve consistency for the high availability side. Having more vital consistency may be helpful in your scenarios.
ClickHouse replication is advanced
Although the ClickHouse database offers great performance while exploring data on a single server, using the replication feature is one of the most effective solutions for the high availability side. In addition, not only providing high availability but also consistent reading operations could be applied from any replica nodes, and the distribution of such operations between multiple replicas is provided by the internal load-balancer mechanism. In replication operations, ClickHouse’s merging process plays an important role in manipulating data in the replicas according to the requirements. When manipulating large amounts of data from clients on the leader node, the data may not be transmitted to replicas in the same order by default. This means, reading operations could be done from replica nodes, but stale data can be read. Using these “select_sequential_consistency” and “insert_quorum” parameters together prevents us from querying from a replica if the data is not up to date. Of course, considering the value of “insert_quorum_parallel” parameter is significant to use this feature. Also, these parameters could provide different solutions if used separately.
ClickHouse is multi-leader and eventually-consistent
So how is it possible to catch the most up-to-date data from the replica side? Actually, not only read operations could be applied only, but also write operations can be done from the same replica node. Because multiple replicas can be leaders at the same time unless otherwise specified. This mechanism is called multi-leader and using the “in_order” load balancing schema which is provided by the distributed engine, allows picking the healthy replica considering the order in the configuration file. Thus, all of the operations could be done in a load-balanced environment. In addition, “can_become_leader” parameter specifies whether the replica can be the leader or not to be responsible for scheduling background merges. Strengthening load-balancer scenarios with these parameters, expands your high availability options.
ClickHouse is distributed
Splitting a large amount of data across different servers is great, but keeping your service closer to where you want it is even more awesome. ClickHouse sharding mechanism is a horizontal scaling solution that stores one ClickHouse database. Improving fault tolerance and query performance is quite possible with this strategy. Also, overcoming technical limitations is very straightforward by using this method.
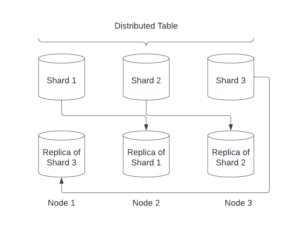
ClickHouse could use a date/time field to shard your large amount of data but giving a specific shard key is also possible to utilize in different territories. As an example, given a three-server scenario, one shard might store records starting with A-I, the other shard records starting with J-P and while the last one stores record for Q-Z. After the Distributed Table is set up, ClickHouse will determine which shard the data belongs in and write/read operations. Briefly, clients don’t need to know which servers will store which shards.
When a distribution table receives a bulk data to write, its mechanism sends them to the particular shards asynchronously, by default. Of course, ClickHouse provides us with an option to specify the distribution table mechanism. Using synchronous architecture is possible instead of the asynchronous option and this mechanism could be determined using the “insert_distributed_sync” parameter. If it is specified as synchronous, all the insert operations are completed on all shards then, the client receives the acknowledgment about concluding the insert operation. The sync or async options have their own pros and cons, and needs to be evaluated which solution is right for your business.
In practical terms, each server must accommodate one shard and other shard’s replicas to reduce fault tolerance in a three-server scenario. If one server becomes unavailable, there is still enough source to read and write operations from the database. On the other hand, it is possible to improve this precaution by increasing the number of replicas on each server.
Conclusion
As a result, running highly available systems is fundamental today, particularly crucial databases and ClickHouse provides lots of solutions according to your requirements. This article gives an overview of the many options between high data protection and high performance to help improve your business.
To learn more about High Availability and Replication in ClickHouse, read the following articles:
- ClickHouse Horizontal Scaling: Replication in ClickHouse
- ClickHouse Horizontal Scaling: Setting up 6-node ClickHouse Infrastructure with Replication & Sharding
- ClickHouse MergeTree: Introduction to ReplicatedMergeTree
- Setting up ClickHouse Cluster Replication with Zookeeper
- ClickHouse Horizontal Scaling: Implementing Parallel Replicas with Dynamic Shards