MergeTree: The Foundation of High-Performance Analytical Data Storage
In the rapidly evolving landscape of big data analytics, the choice of storage engine fundamentally determines system performance, scalability, and operational efficiency. MergeTree, the cornerstone storage engine family of ClickHouse, represents a paradigm shift in how analytical databases handle massive datasets. Designed specifically for high data ingest rates and enormous data volumes, MergeTree has established itself as the default table engine for analytical workloads, providing unparalleled performance through innovative architectural decisions and engineering excellence.
This comprehensive exploration delves into the intricate architecture, sophisticated engineering principles, and exceptional performance characteristics that make MergeTree the preferred choice for organizations processing petabytes of data daily. From its columnar storage foundation to its intelligent merge strategies, MergeTree exemplifies how thoughtful engineering can transform data analytics capabilities.
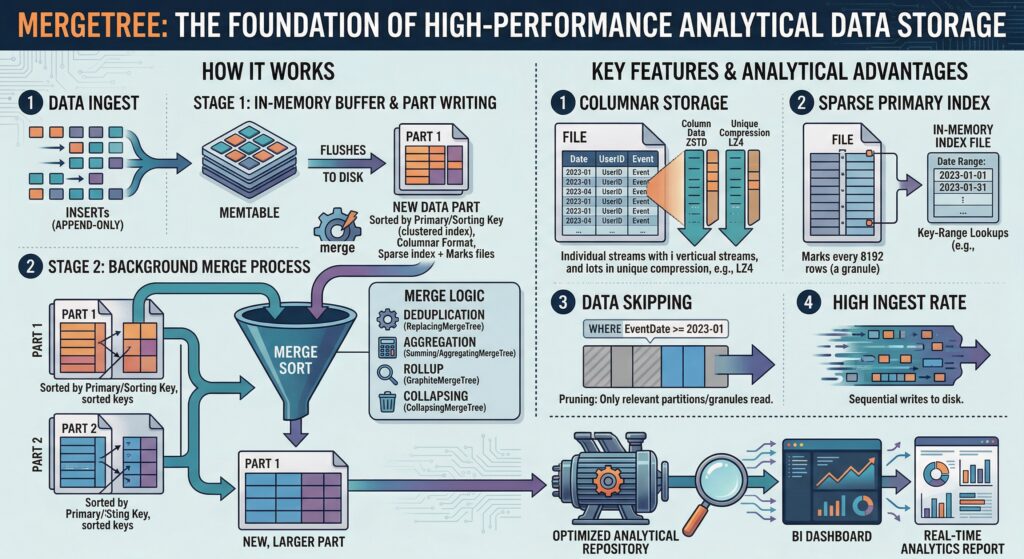
Columnar Storage Foundation
At its architectural core, MergeTree implements a true column-oriented storage model that fundamentally differs from traditional row-based systems. This design choice enables several critical performance advantages for analytical queries. Unlike conventional databases that store complete records together, MergeTree organizes data by columns, allowing the system to read only the specific columns required for a query, dramatically reducing I/O overhead and improving cache efficiency.
The columnar approach proves particularly advantageous for analytical workloads where queries typically aggregate data across many rows but require only a subset of columns. This architectural decision enables MergeTree to achieve compression ratios and query speeds that would be impossible with row-oriented storage systems.
Parts and Partitioning System
MergeTree’s data organization revolves around the concept of “parts” – horizontal divisions of data that form the fundamental storage units. Each part represents a self-contained segment of the table, stored in its own directory and maintained in primary key sort order. This partitioning strategy, based on Log-Structured Merge (LSM) tree principles, enables efficient data management and query optimization.
The partitioning system operates on multiple levels. At the highest level, tables can be partitioned by date or other criteria, allowing for efficient data lifecycle management and query pruning. Within each partition, data is further divided into parts based on insertion patterns and merge operations, creating a hierarchical structure that optimizes both storage efficiency and query performance.
LSM Tree Implementation
The underlying LSM tree architecture provides MergeTree with its exceptional write performance and storage efficiency. New data insertions create new parts rather than modifying existing data structures, ensuring that write operations remain consistently fast regardless of table size. This immutable approach eliminates the need for complex locking mechanisms during writes while maintaining data consistency.
The LSM tree design also enables efficient background processing through dedicated merge threads that continuously optimize data organization without impacting query performance. This separation of concerns – fast writes through part creation and optimized reads through background merging – represents a fundamental engineering advantage over traditional database architectures.
Engineering Design Principles: Intelligent Indexing and Processing
Sparse Primary Indexing Innovation
MergeTree’s sparse primary indexing system represents a revolutionary approach to data access optimization. Unlike traditional databases that maintain dense indexes with entries for every row, MergeTree creates sparse indexes with one entry per 8,192 rows, known as granules. This design dramatically reduces memory requirements while maintaining exceptional query performance.
The sparse indexing strategy works by organizing data into granules – blocks of consecutive rows sorted by the primary key. When processing queries, ClickHouse uses the sparse index to identify relevant granules and skip entire sections of irrelevant data. This approach can eliminate the need to read millions of rows during query execution, resulting in sub-second response times for complex analytical queries across massive datasets.
The primary key in MergeTree serves dual purposes: it determines the physical sort order of data within each part (functioning as a clustered index) and provides the foundation for the sparse indexing system 1. This dual functionality ensures that both storage efficiency and query performance are optimized through a single, well-designed mechanism.
Background Merge Architecture
The engineering elegance of MergeTree becomes apparent in its sophisticated background merge system. The MergeTreeData class serves as the central coordinator, managing collections of immutable data parts and orchestrating background operations that continuously optimize data organization without impacting system availability.
Background merges operate on two primary strategies: horizontal and vertical merging. Horizontal merging reads all columns simultaneously, performs merge-sort operations, and writes optimized parts to disk. Vertical merging first processes ORDER BY columns, establishes the sort order, and then applies this permutation to remaining columns. The choice between these strategies depends on data characteristics and performance requirements, demonstrating MergeTree’s adaptability to diverse workload patterns.
The merge process also recreates metadata, including secondary data-skipping indexes, column statistics, checksums, and min-max indexes. This comprehensive approach ensures that all optimization structures remain current and effective as data evolves, maintaining consistent performance across the entire data lifecycle.
Immutable Data Parts Strategy
The immutable data parts architecture provides MergeTree with exceptional reliability and performance characteristics. Once created, parts remain unchanged until they are merged with other parts to form new, optimized structures. This approach eliminates many traditional database challenges, including complex locking mechanisms, update anomalies, and consistency issues during concurrent operations.
Immutability also enables sophisticated caching strategies and predictable performance patterns. Since parts never change, cached data remains valid indefinitely, and query planners can make optimization decisions based on stable metadata. This predictability extends to backup and replication operations, where immutable parts can be safely copied without concerns about concurrent modifications.
Performance Characteristics: Optimized for Scale
Query Optimization Through Intelligent Pruning
MergeTree’s performance advantages become most apparent in its query optimization capabilities. The sparse primary index enables aggressive data pruning, where entire parts or granules can be eliminated from consideration based on primary key ranges. This pruning capability allows ClickHouse to skip over large ranges of irrelevant rows during query execution, dramatically reducing the amount of data that must be processed.
The effectiveness of this pruning depends heavily on primary key selection and data distribution. Well-designed primary keys that align with common query patterns can result in orders-of-magnitude performance improvements, while poorly chosen keys may limit optimization opportunities. This relationship between schema design and performance makes primary key selection one of the most critical architectural decisions in MergeTree implementations.
Compression and Storage Efficiency
MergeTree’s columnar architecture enables sophisticated compression strategies that significantly reduce storage requirements and improve I/O performance. Different compression codecs can be applied to individual columns based on their data characteristics, optimizing both storage density and decompression speed.
The ORDER BY key plays a crucial role in compression effectiveness by determining on-disk data layout. When data is properly sorted, similar values are stored adjacently, enabling compression algorithms to achieve higher ratios. This relationship between sort order, compression, and query performance demonstrates the interconnected nature of MergeTree’s architectural decisions.
Scalability and Concurrency
MergeTree’s architecture scales exceptionally well across multiple dimensions. Horizontal scaling is achieved through distributed table engines that coordinate multiple MergeTree instances across cluster nodes. Vertical scaling benefits from the engine’s efficient memory utilization and CPU optimization, particularly in environments with substantial RAM for caching hot data.
The background merge system ensures that performance remains consistent as data volumes grow. Unlike traditional databases where performance may degrade with table size, MergeTree maintains predictable query response times through continuous optimization of data organization. This characteristic makes it particularly suitable for applications with ever-growing datasets and consistent performance requirements.
Optimization Strategies: Maximizing Performance
Hardware Configuration Best Practices
Optimal MergeTree performance requires careful attention to hardware configuration. Memory recommendations typically start at 64GB+ RAM to effectively cache hot data and support concurrent query processing. The substantial memory allocation enables ClickHouse to maintain sparse indexes, compressed data blocks, and query intermediate results in memory, dramatically reducing disk I/O requirements.
Storage configuration significantly impacts both query and merge performance. NVMe SSDs configured in RAID-10 arrangements provide the high IOPS and bandwidth necessary for efficient background merges and concurrent query processing. The storage subsystem must handle both sequential reads for analytical queries and random I/O patterns during merge operations, making high-performance storage essential for optimal results.
Schema Design and Primary Key Selection
Effective schema design represents the most impactful optimization strategy for MergeTree implementations. Primary key selection should align with the most common query patterns, enabling maximum benefit from sparse indexing and data pruning capabilities. Keys that support range-based filtering and enable efficient partition elimination provide the greatest performance advantages.
The ORDER BY clause determines both physical data layout and compression effectiveness. Columns with high cardinality or frequent filtering requirements should be prioritized in the key definition, while maintaining awareness of the impact on insert performance and storage requirements.
Merge Strategy Optimization
Understanding and optimizing merge behavior is crucial for maintaining consistent performance. The choice between horizontal and vertical merge strategies depends on table schema, query patterns, and data characteristics. Tables with many columns may benefit from vertical merging, while simpler schemas often perform better with horizontal strategies.
Avoiding unnecessary OPTIMIZE FINAL operations is critical for maintaining system performance. These operations force immediate merging of all active parts, potentially creating resource contention and impacting concurrent operations. Instead, allowing background merges to operate naturally typically provides better overall system performance.
Advanced Configuration Tuning
Performance tuning should follow an iterative approach, with careful measurement of each optimization’s impact. Key configuration parameters include max_memory_usage for balancing query resource allocation, merge-related settings for controlling background operations, and cache configurations for optimizing repeated query patterns.
Filesystem cache behavior significantly impacts performance measurement and optimization efforts. Disabling filesystem cache during testing (SET enable_filesystem_cache = 0) provides more accurate performance measurements and helps identify genuine optimization opportunities rather than cache-related improvements.
Real-World Applications and Use Cases
Cloud-Native Deployments
Modern MergeTree implementations increasingly leverage cloud-native architectures through engines like SharedMergeTree, which optimizes performance for shared storage systems including Amazon S3, Google Cloud Storage, and Azure Blob Storage. These implementations maintain MergeTree’s performance characteristics while providing the scalability and cost benefits of cloud object storage.
S3-backed MergeTree configurations demonstrate the engine’s architectural flexibility. Local storage maintains the MergeTree file structure and metadata, while actual data bytes reside in object storage. This hybrid approach enables cost-effective storage of massive datasets while preserving the query performance characteristics that make MergeTree exceptional.
High-Volume Analytics Platforms
Organizations processing petabytes of data daily rely on MergeTree’s ability to maintain consistent performance across massive scales. The engine’s design for high data ingest rates makes it particularly suitable for real-time analytics platforms, log processing systems, and IoT data collection scenarios where continuous data arrival must be balanced with complex analytical query requirements.
The separation of storage and compute capabilities, particularly through S3BackedMergeTree implementations, enables organizations to scale storage and processing resources independently. This flexibility proves essential for applications with variable query loads and continuously growing datasets.
Data Lake Acceleration
MergeTree serves as an acceleration layer for data lake architectures, providing dramatically better performance than reading open table formats directly. The sparse primary index and optimized data layout enable ClickHouse to deliver sub-second response times for queries that might require minutes or hours when executed against raw data lake formats.
This acceleration capability makes MergeTree an ideal choice for organizations seeking to maintain data lake flexibility while providing interactive analytics capabilities. The engine can ingest data from various sources, optimize it for analytical access, and provide consistent high performance across diverse query patterns.
Conclusion
MergeTree represents a fundamental advancement in analytical database storage engine design, combining innovative architectural decisions with sophisticated engineering implementation to deliver exceptional performance at scale. Its columnar storage foundation, sparse indexing system, and intelligent merge strategies create a synergistic effect that enables organizations to process massive datasets with unprecedented efficiency.
The engine’s success stems from its holistic approach to performance optimization, where every architectural decision – from LSM tree implementation to background merge strategies – contributes to overall system effectiveness. This comprehensive design philosophy ensures that MergeTree remains performant across diverse workloads and scales gracefully as data volumes and query complexity increase.
As data analytics requirements continue to evolve, MergeTree’s flexible architecture and continuous optimization capabilities position it as a cornerstone technology for next-generation analytical platforms. Organizations seeking to unlock the full potential of their data assets will find in MergeTree not just a storage engine, but a complete foundation for high-performance analytical computing.
The combination of proven architectural principles, sophisticated engineering implementation, and real-world performance validation makes MergeTree an essential technology for any organization serious about analytical data processing. Its continued evolution and adaptation to cloud-native environments ensure that it will remain at the forefront of analytical database technology for years to come.