Access control solutions are classified broadly into 4 categories: Discretionary Access Control, Role Based Access Control, Rule Based Access Control and Mandatory Access Control. I will not be diving into the details of each as there exists plenty of articles in the web describing the unique characteristics of each. Here we are trying to explore a custom access control solution we have developed for Chistadata’s cloud DBaaS solution. Our needs demanded a solution that offers the flexibility of a DAC while also is nimble as an RBAC when it comes to assigning permissions to a user.
What did I mean by that?
The Requirement
Chistadata DBaaS is a cloud DBaaS offering around Clickhouse. The challenges here are similar to the ones faced by providers like AWS or Azure when it comes to user access management. In our case we have multiple layers of abstractions under which resources exist. Highest level is “Organization” and inside it comes a “Workspace” and there can be multiple “Clusters” under a workspace. Authorized users can create or delete workspaces and clusters and access specific functionalities within a cluster like the query editor, monitoring dashboards, backup and restore and the likes. We are required to manage access to a dynamic and customizable set of resources like workspaces and clusters. One can easily see where a conventional RBAC system falls short. A Role-Permission hierarchy cannot keep up with the nested levels of complexity this system will easily reach. The system will end up creating permissions like workspace_1_cluster_2_query, and workspace_1_cluster_3_backup which has two issues.
- Admins will be forced to manage a list of permissions that can easily grow into the order of hundreds, in a medium sized organization.
- It becomes difficult to define admin accesses which must cover all resources created so far and will be created in the future.
This called for a custom access control system
The Design
We can see that the structure of these resources is hierarchical and can be represented using a tree where each feature or functionality is a node which can have children depending on what action it is expected to do. For example a “Create Workspace” function is a terminal whereas a particular workspace like “Workspace-1” is not. Workspace-1 has its own page which has child components which also require access control. This recursive structure is dynamic and will change based on customer demands.
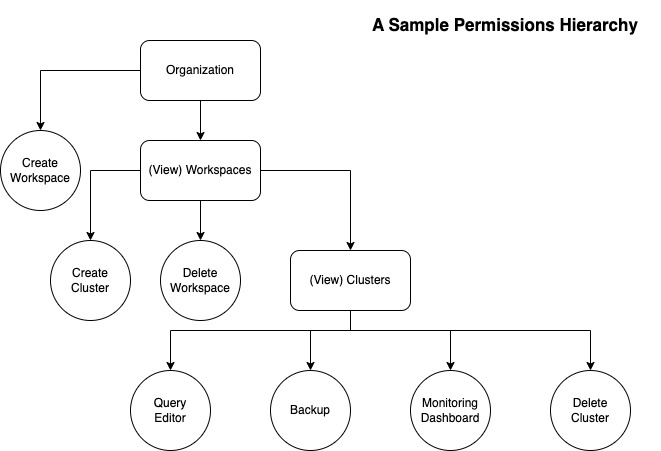
The above idea is implemented in code using three important entities.
- Feature Hierarchy structure
- User Permissions structure
- Access Path
Let us look what each of them are.
Feature Hierarchy
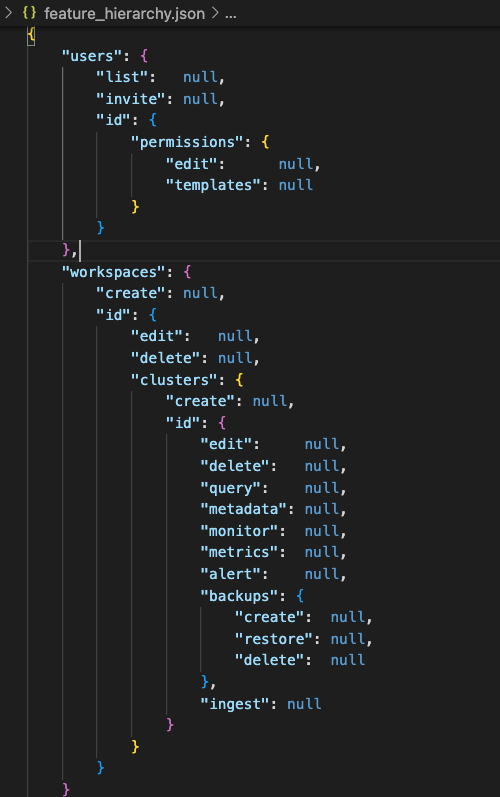
It represents the hierarchical relationship of features of functionalities that exist in the system. It has the below characteristics.
- Exhaustive: Every resource type that needs to be access controlled must be represented in this structure.
- Enumerable resources: Properties of resources which are enumerable are represented using the “id” field. An id simply tells the permission system that “for every unique resource of the parent type, following resources exist“. In the above example if you look at the “id” field inside “clusters“, it means that every cluster can contain edit, delete, query, metadata….etc.
User Permissions
Permissions of a user is represented in the backend using a JSON or a map as shown below which are called user_permissions. Such a permissions structure will exist for every user under an organization. A user_permissions table will store this map against the username and organization_id.

User permissions is not exhaustive as this structure may or may not contain all the resources in the system and specific to a user as this will only contain entries to which a user has access to.
As of now you might be confused about the nulls and the wildcards so let’s explore the semantics of these structures.
- nulls: A null against a resource node has different meanings in feature_hierarchy and user_permissions.
- Feature Hierarchy: A null value indicates a terminal or leaf node in the hierarchical tree structure.
- User Permissions: A null value indicates unrestricted access to the resource which has the value. That is if a user_permissions struct has null value against workspaces it means that this user has access to every single resource, recursively, inside the workspaces node in feature_hierarchy.
- wildcards (only * supported currently): Wildcards are applicable only to user_permissions, by their nature. While evaluating user access a user will have access to every resource that matches the wildcard in the given access_path.
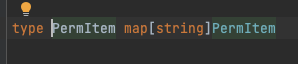
Both feature_hierarchy and user_permissions can be represented with a single recursive type definition in Go, which we called a PerItem, as below.
Access Path
An access path is simply the path to a particular resource within the feature hierarchy. It is used to instruct the middleware function as to what access is required to access the given resource (endpoint in our case). A very basic access path can be something like /workspaces/create
Every element which is separated with a slash is a called a path_part.
But it is more than just a JSON path as it has to serve the specific purpose of securing resource. For example how can you mention that an enumerable resource with a particular id should be accessible? For example cluster create within workspace with id-12 should be accessible only to those users with access to that workspace. This is difficult with plain text as interpreting access requires extraction of parameters from the current request.
Let me introduce to you parameter extractors or param_extractors. A parameter extractor is simply a path_part which tells the authorization middleware to substitute it with unique identifiers or other fields from the different types of inputs in an HTTP request like path params, query params, JSON bodies, headers and user details from authentication cookie.
There are five types of param_extractors available.
- u(param_name): Extracts a root level string from the JWT token such as the username or email.
- p(param_name): Extracts path param with param_name from the URL.
- q(param_name): Extracts query param with param_name from the URL.
- h(param_name): Extracts header with param_name.
- j(param_name): Extracts a root level string from the JSON body with param_name.
Below is an example of param_extractors being used.

Now let’s talk a little bit about how these concepts are implemented.
The Implementation
Securing the endpoint
The developer must specify where within the feature_hierarchy a particular resource path exists in order to enforce permissions as shown below.
The path must be an existing one inside feature_hierarchy.
The Middleware
The authorization middleware function verifies whether the user issuing the current request has access to the secured resource. The Authorize function is added as a gist for reference.
In the middleware function we extract and substitute parameters inside the path to end up with an effective path which looks like this
/workspaces/id-12/clusters/id-10
This is fed into a tree traversal algorithm which traverses both the user_permissions and feature_hierarchy, simultaneously, while also matching against wildcards to check if the user has access.
Fairly straightforward, right? But the solution isn’t complete yet. What about the client? How will we show and hide parts of the UI to which the user does not have access to? To understand the challenge, think about how we can hide workspace-1 while showing workspace-2. Straightforward thinking leads us to replicating whatever logic we have built in the backend in the UI side.
This will
- Double the probability of bugs, which is already high
- Make maintenance challenging
The Client/UI Side
What we have done is to introduce a fourth type of entity which we call Effective Permissions structure. This is basically just the Feature Hierarchy where every enumerable entity is enumerated and generated specifically for the current user.
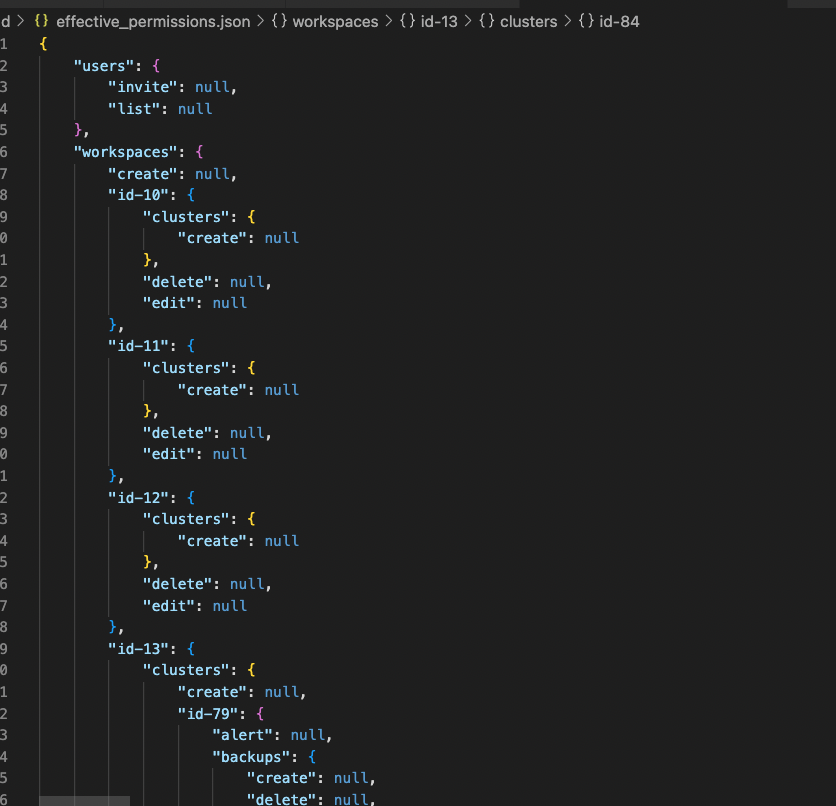
The algorithm used for this is relatively more complex than the one above used to check backend permissions.
If a user has access to resources “a” and “b” under workspace-1 and resource “c” under workspace-* (all workspaces), then their effective access on workspace-1 must be a union of both i.e “a”, “b” and “c”. Such conditions make this piece relatively tougher to implement in comparison to the backend permission check which is linear during tree traversal.
And the client simply has to do a single traversal of this structure to determine whether or not the user has access to a particular resource.
However access to some information should be restricted at the backend itself and should not be sent to client side. Information about workspaces and clusters is such. The above example however demonstrates the capability to do so, if the need arises.
Sample code for filtering out entities for which the current user does not have access:
Conclusion
The quest to build general purpose access control solutions is an old one and many people smarter and more qualified than the author has attempted it before. The intention here was simply to build a system that is extensible enough to accommodate the dynamic nature of a DBaaS offering while also being simple to understand and maintain. I have spent close to 10 days before finalizing on an approach, partly because of the lack of resources available on this niche topic (since most applications can live with a conventional RBAC with unidimensional permissions). I hope that this has helped.